UNETR: Transformers for 3D Medical Image Segmentation
Notes
Highlights
- The goal is to take advantage of the transformer’s capacity to learn long-range dependencies to overcome the limitations of CNNs
- The proposed architecture, UNETR (UNEt TRansfomers) uses a transfomer as an encoder and convolutional layer in the decoder to compute the segmentation output
- The method is validated on the Multi Atlas Labeling Beyond The Cranial Vault (BTCV) dataset for multiorgan segmentation and the Medical Segmentation Decathlon (MSD) dataset for brain tumor and spleen segmentation tasks.
- Method shows new state-of-the-art performance on the BTCV leaderboard.
Methods

Architecture
-
This is transformer-based architecture, so you can refer to this tutorial if you need more details.
-
3D input volume \(\mathbf{x} \in \mathbb{R}^{H \times W \times D \times C}\) is divided into non-overlapping patches of size \((P, P, P)\) which are flattened to give \(N\) tokens arrange in a matrix \(\mathbf{x_v} \in \mathbb{R}^{N \times (P^3.C)}\)
-
A linear layer is used to project the patches into a \(K\) dimensional embedding space, then a 1D learnable positional embedding is added giving \(\mathbf{z}_{0} \in \mathbb{R}^{N \times K}\) :
with \(\mathbf{E} \in \mathbb{R}^{(P^3.C) \times K}\) the projection matrix to learn
-
Note: no class token is involved in this architecture since the targeted task is not classification but segmentation
-
Then this embedding is used as the input of multiple transformer block like in a classical transformer architecture (see tutorial for more details).
-
At the end of each transformer block \(l\) we have a matrix \(\mathbf{z}_l \in \mathbb{R}^{N \times K}\) with \(N = (H * W * D)/P^3\)
-
These matrixes are extracted for different transformer block (\({3, 6, 9, 12}\)) and reshape into a feature map of shape \(\frac{H}{P} * \frac{W}{P} * \frac{D}{P} * K\)
-
At the bottleneck, deconvolutional (transposed convolution) layer is applied to increase the resolution of the feature map. Then the resized feature map is concatenated with the feature map of the previous transformer block and processed by a convolutional layer.
-
This process is repeated for all the other subsequent layers up to the original input resolution where the final output is fed into a 1×1×1 convolutional layer with a softmax activation function to generate voxel-wise segmentation map.
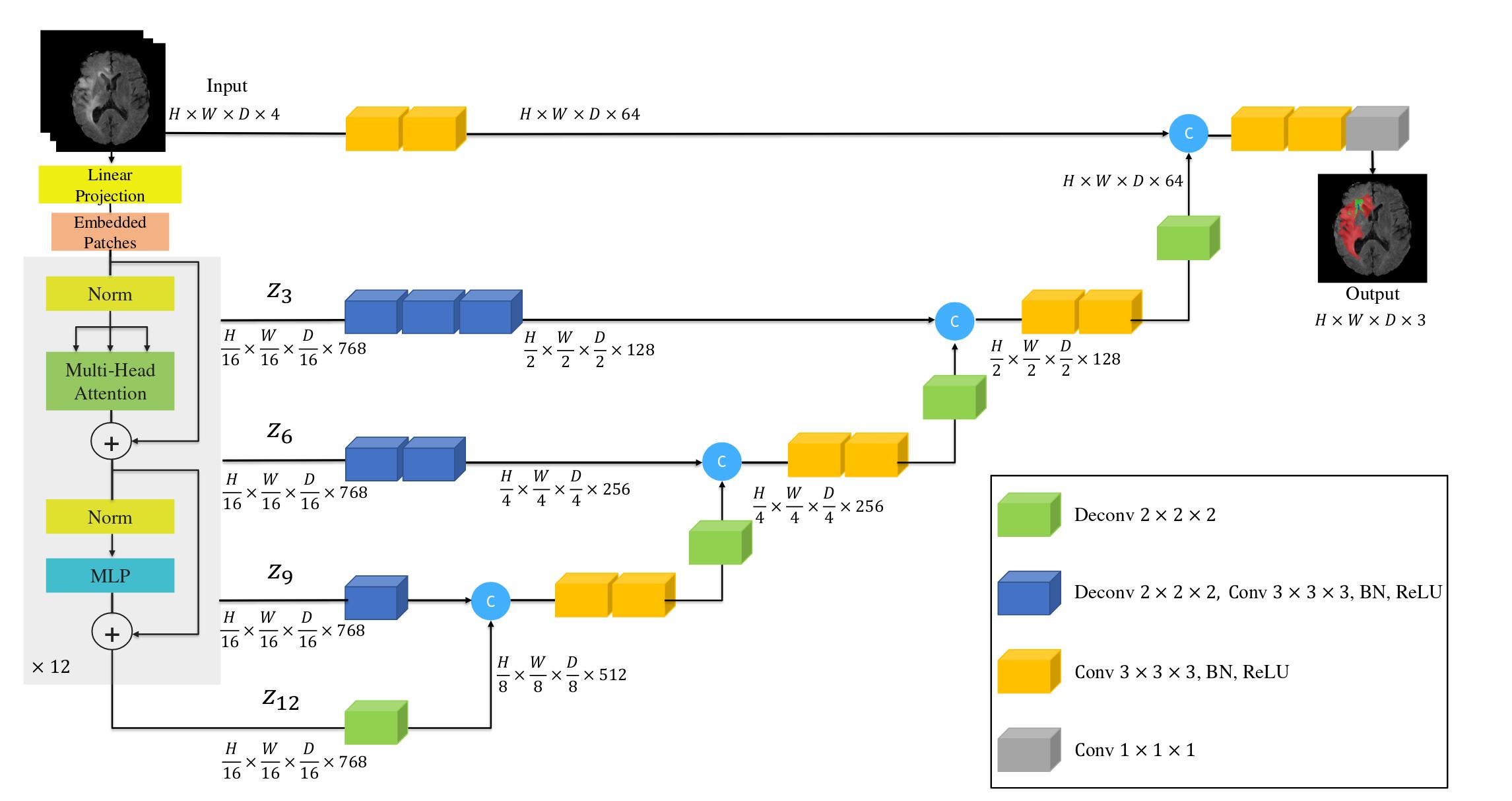
Experiments
- Loss is a combination of soft dice and cross-entropy
- Method is evaluated on BTCV and MSD datasets
- BTCV : 30 patients with abdominal CT scans where 13 organs are annotated (13 class segmentation problem)
- MSD : 484 multi-modal and multi-site MRI (Flair, T1w, T1gd, T2w) for the brain tumor segmentaion task and 41 CT scan for the spleen segmentation task
-
Dice and 95% Hausdorff Distance (HD) are used as evaluation metrics
- Transformer parameters used : \(L=12\) transformer block, embedding size of \(K=768\), patch size of \(16 * 16 * 16\)
-
Average training time : 10 hours for 20 000 epochs
- Note : the transformer backbone is not pre-trained at all
Results
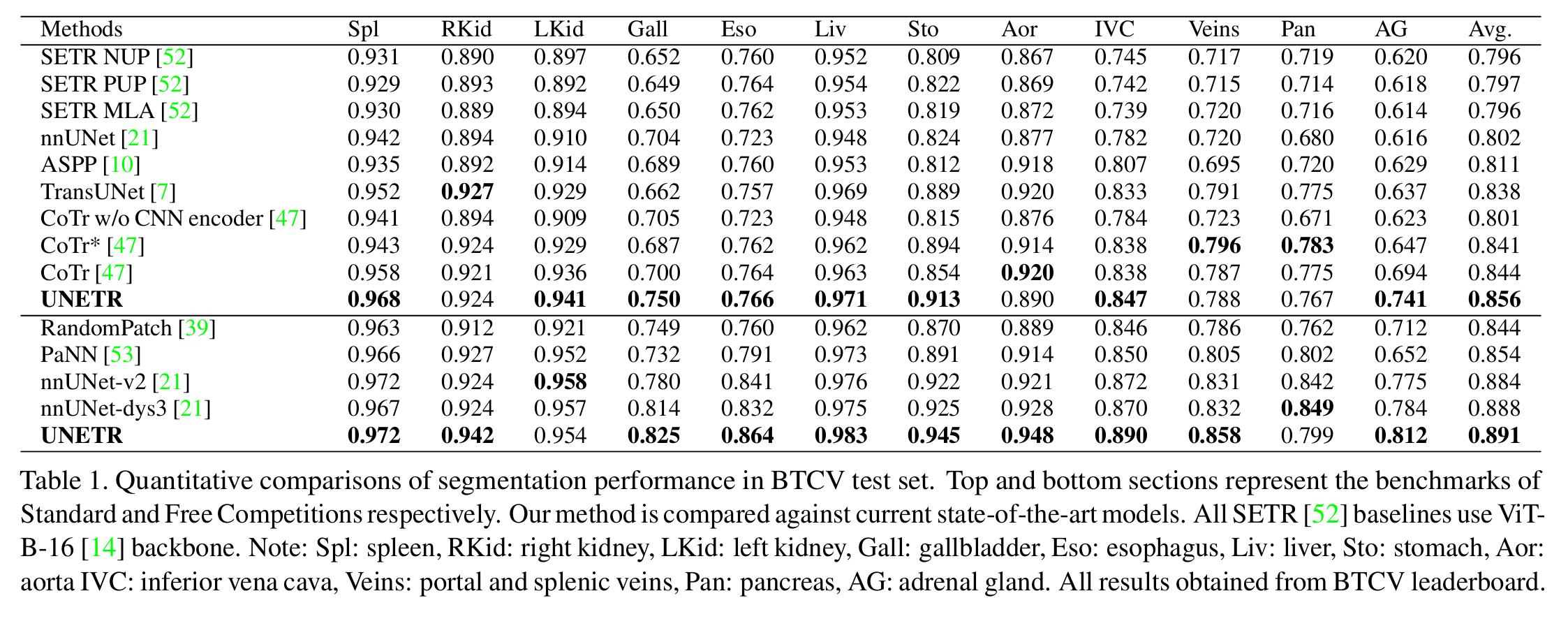
As seen in the table below, UNETR outperforms the state-of-the-art methods on the BTCV leaderboard ( which are CNN or transformer based methods123)
Same for the MSD dataset

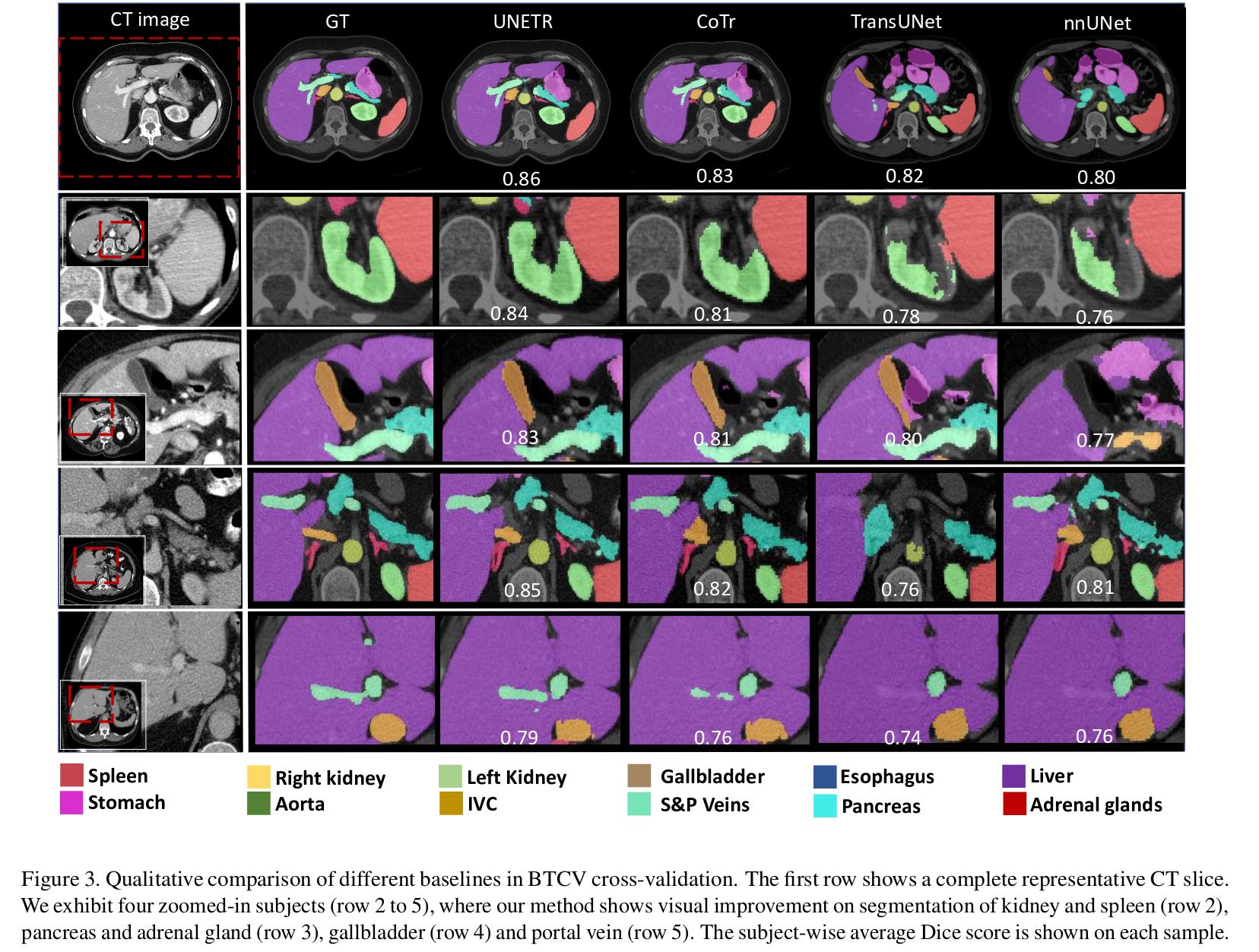
Some visual results on the BTCV dataset::
Ablation studies
Authors compare their decoder architecture with three other designs called Naive UPsampling (NUP), Progressive UPsampling (PUP) and MuLti-scale Aggregation (MLA) 1

They also compare model complexity with other architectures:
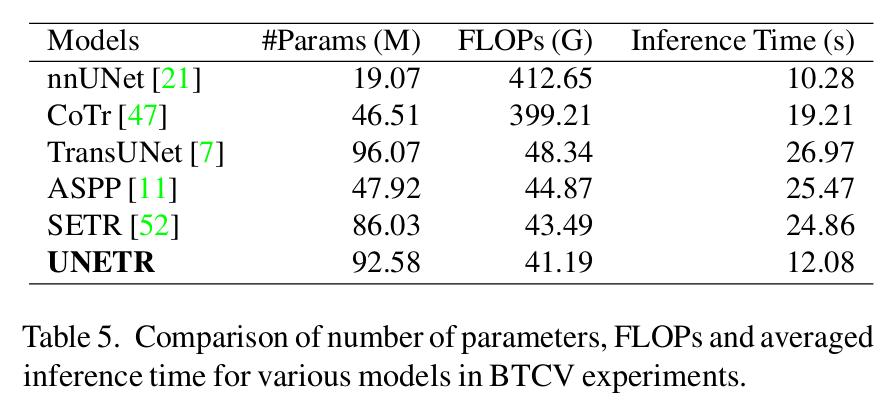
Conclusions
UNETR has taken a first step towards transformer based models for segmentation
References
-
Sixiao Zheng et al, Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers, Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2021) ↩ ↩2
-
Jieneng Chen et al, Transunet: Transformers make strong encoders for medical image segmentation, arXiv preprint (2021) ↩
-
Yutong Xie et al, Cotr: Efficiently bridging cnn and transformer for 3d medical image segmentation, International conference on medical image computing and computer-assisted intervention (2021) ↩