Quantifying Attention Flow in Transformers
Introduction
This paper presents two methods, Attention Rollout and Attention Flow, that allow to vizualise the attention to the input tokens. It was designed for the original NLP transformer1 but the authors of the Vision Transformer2 showed that Attention Rollout still works with images.

Highlights
- Attention weights don’t allow to vizualise attention to input in deep layers due to lack of token identifiability
- They propose two simple methods to vizualise attention to input tokens in a more interpretable way : Attention Rollout and Attention Flow
- Complexity of \(O(d*n^2)\) for attention rollout and \(O(d^2*n^4)\) for attention flow with \(d\) the depth of the model and \(n\) the number of tokens
Methods
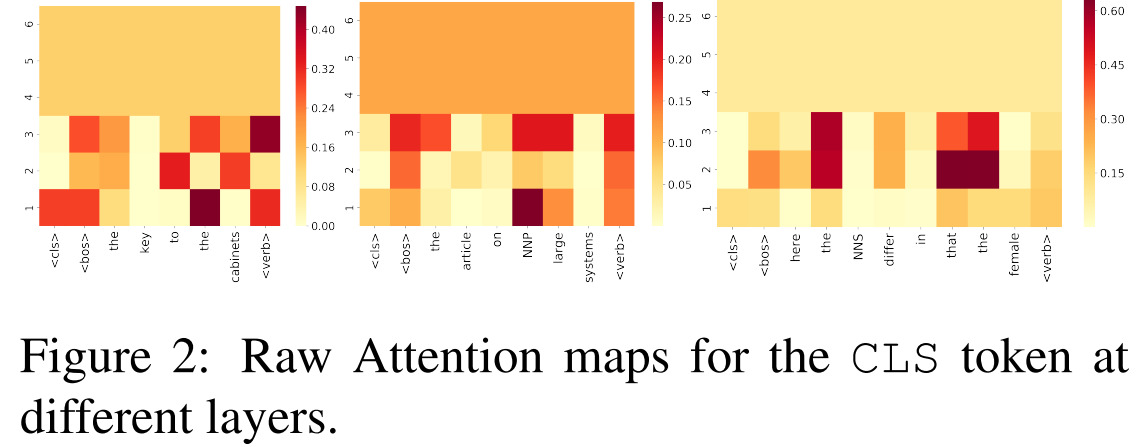
With raw attention maps, information from different tokens gets increasingly mixed after each layer and become uniform after a few layers.
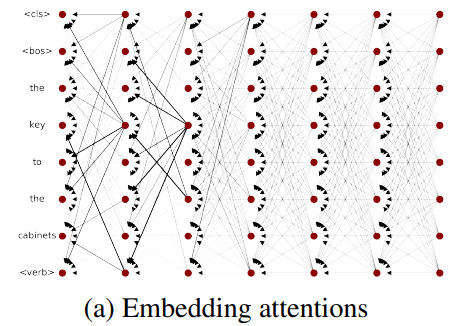
Moreover, raw attention maps don’t take into account the residual connection in the transformer block (\(V_{l+1} = V_l + W_{att}V_l\), with \(l\) the layer and \(W_{att}\) the attention matrix.)
To account for these residual connections they add an identity matrix to the attention matrix and re-normalize : \(A = 0.5W_{att} + 0.5I\)
It is possible to analyze each head separately but in the paper they propose to average the attention at each layer over all heads.
Attention Rollout
We can see the network as a graph with :
- Nodes : tokens
- Edges : attention from the nodes of a layer to those of the previous layers
- Weights : attention weights
In Attention Rollout, the weights are considered as the proportion of information transfered between two nodes.
To compute the attention from layer \(i\) to layer \(j\) we can use this equation :
\[\tilde{A}\left(l_{i}\right)=\left\{\begin{array}{ll} A\left(l_{i}\right) \tilde{A}\left(l_{i-1}\right) & \text { if } i>j \\ A\left(l_{i}\right) & \text { if } i=j \end{array}\right.\]With \(\tilde{A}\) the attention rollout. To compute input attention \(j\) is set to 0.
Attention Flow
In Attention Flow, the weights are considered as the capacity of the edge. In graph theory, the flow of the graph must satisfy two conditions :
- Capacity constraint : for each edge the flow should not exceed its capacity
- Flow conservation : for all nodes (except source and target) the input flow is equal to the output flow
Using any maximum flow algorithm it is possible to compute the maximum attention flow from any node of a hidden layer to any input node.
Experiment
- Task : verb number prediction (i.e. singularity or plurality of a verb in a sentence)
- Model : GPT-2 Transformer blocks. 6 layers, 8 heads and embedding size of 128.
- They add a Class Token and use its embedding for the final classification
Results
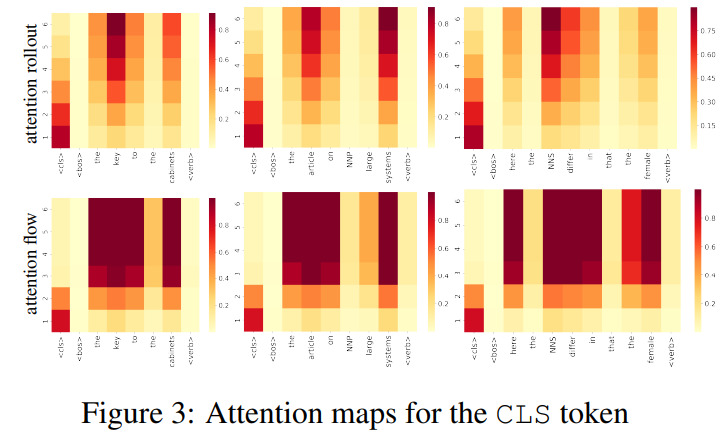
Conclusions
- Attention rollout is more focused than attention flow
- Attention flow indicates a set of tokens that are important for the final decision