Token Merging: Your ViT But Faster
Notes
- Code is available on GitHub: https://github.com/facebookresearch/tome.
Highlights
- Introduce a novel token merging strategy;
- Increase the throughput of existing ViT models with or without training.
- Minimal accuracy drop compared to the existing pruning technique.
Introduction
Transformers are widely used in all kinds of domains, from audio processing to image recognition. However, those transformer models can be massive, making them difficult to train and run. Thus, the reproduction of results are hard. To leverage these issues, pruning has been introduced to enable a faster model. Pruning removes less important tokens based on the metrics computed on the tokens.
Pruning has its owns limitations:
- information loss from pruning limits number of tokens that can be reduced
- some pruning methods require re-training the models, etc.
The authors state that their token merging (ToMe) method is as fast as pruning with higher accuracy. Instead of pruning tokens, they combine them. By doing so, they observe up to 2\(\times\) speed-up for the training of ViT models.
Architecture

In each attention block, \(r\) tokens are merged. Over \(L\) blocks, \(rL\) tokens are gradually merged. Varying \(r\) gives a speed-accuracy trade-off.
Class token and distillation token are excluded from merging.
Main ideas:
- Define token similarity:
- Compute a dot product similarity metric (e.g. cosine similarity) between the keys, \(K\) (averaged from all heads) of each token.
- Bipartite Soft Matching (Refer the figure above)
- The features of merged tokens are averaged.
- Tracking Token Size:
- Merged tokens no longer represent one patch size. To handle this, proportional attention is used. \(A = \text{softmax}(\frac{QK^\top}{\sqrt{d}} + \text{log}(s))\), where \(s\) is a row column containing the number of patches each token represents.
- Train with merging:
- Training with ToMe is not necessary, but it can be done to improve accuracy or speed up training.
- To train, the token merging is treated as a pooling operation and backprop through merged tokens as if the average pooling was used.
Ablation study:
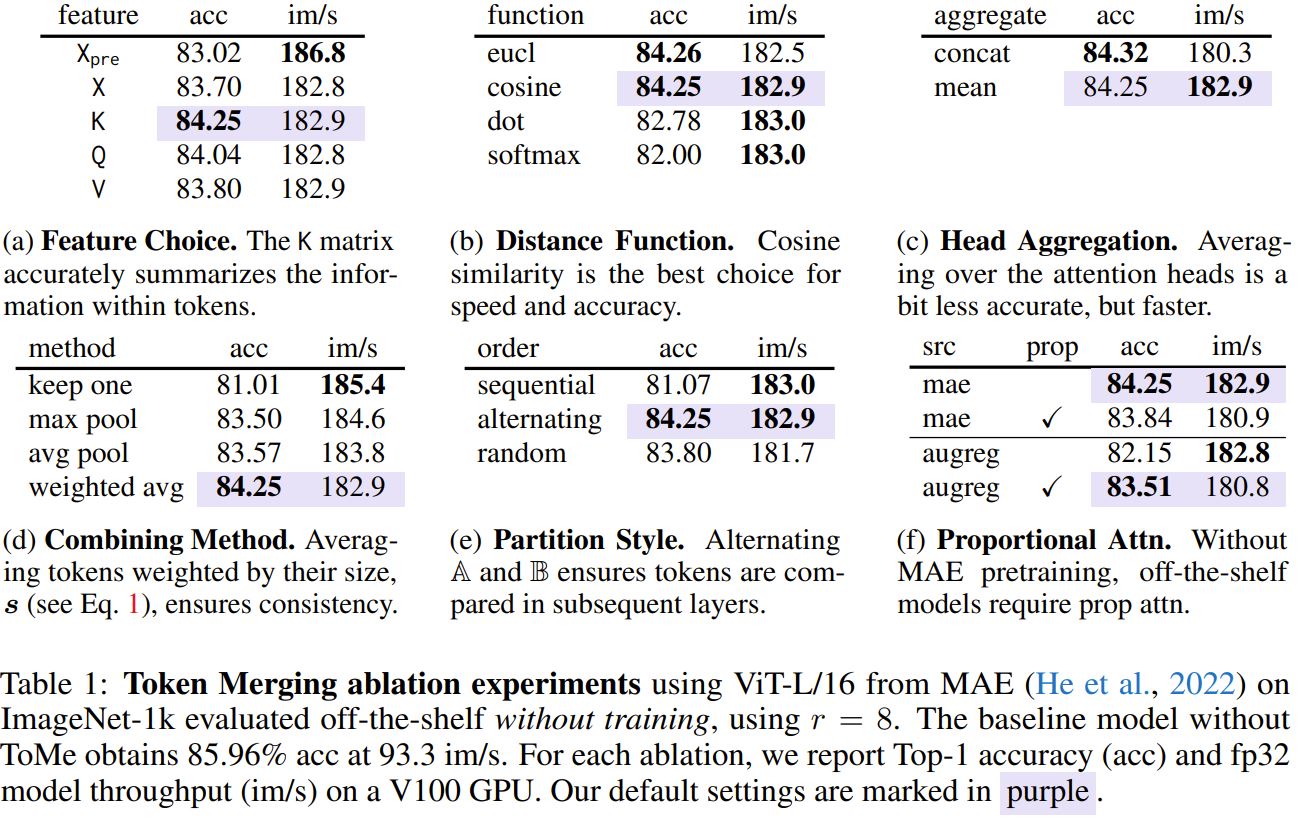
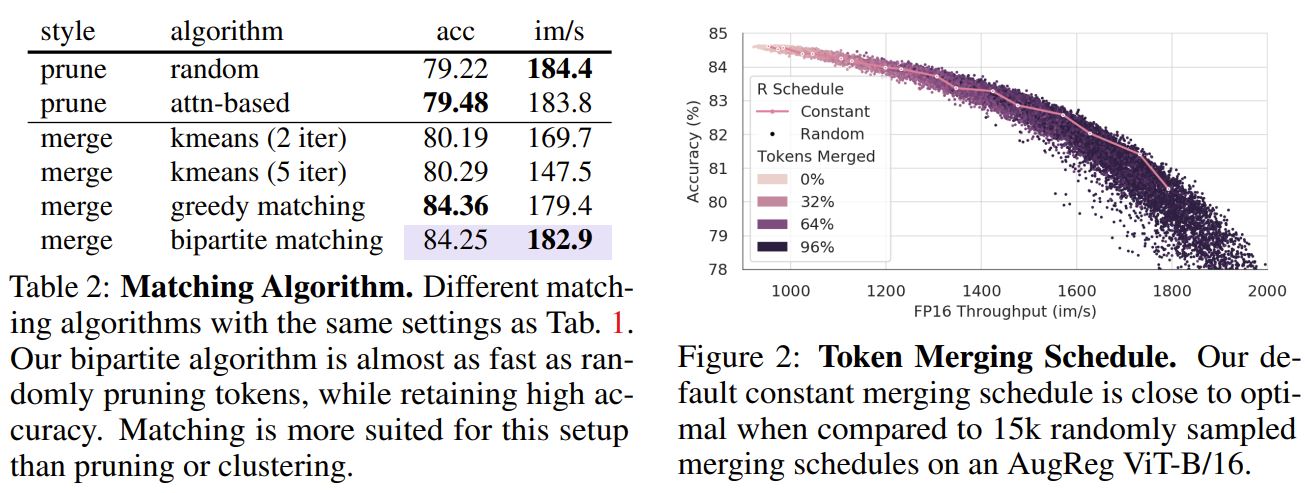
Benchmarking datasets
ToMe was benchmarked on:
- ImageNet-1k
- Kinetics-400 (Human action video clips)
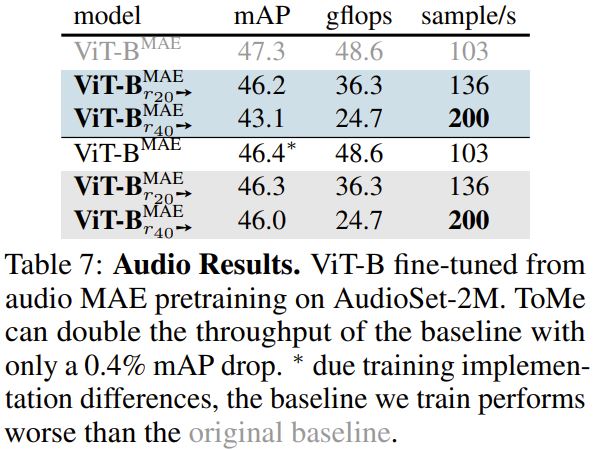
- AudioSet-2M
Results
The comparisons were between the original transformer models without ToMe, ToMe being applied to the models off-the-shelf (without retraining), and the models retrained with ToMe.
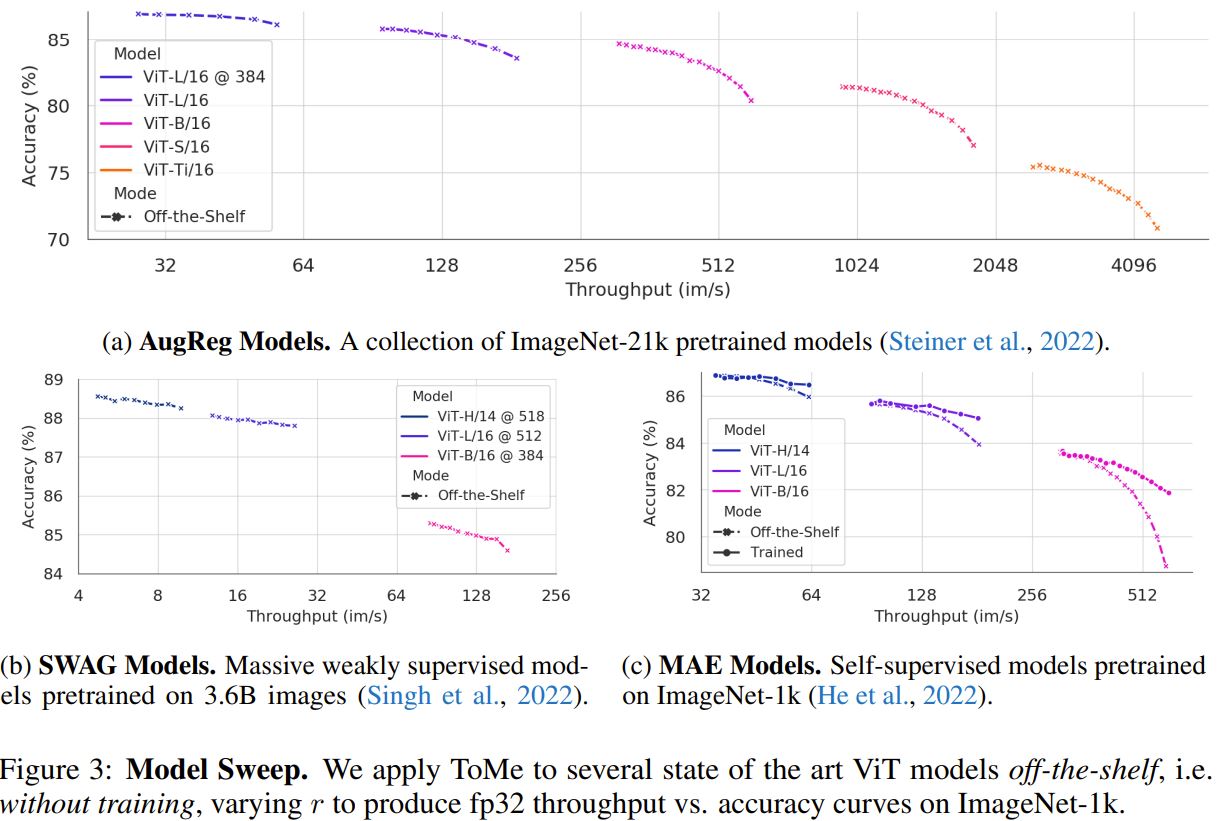 Both AugReg and SWAG are ViT models pretrained on a large supervised (or weakly supervised) pretraining dataset and fine-tuned on ImageNet-1k. Meanwhile, MAE is a self-supervised pretraining method for ViT with models pretrained and fine-tuned on ImageNet-1k.
Both AugReg and SWAG are ViT models pretrained on a large supervised (or weakly supervised) pretraining dataset and fine-tuned on ImageNet-1k. Meanwhile, MAE is a self-supervised pretraining method for ViT with models pretrained and fine-tuned on ImageNet-1k.
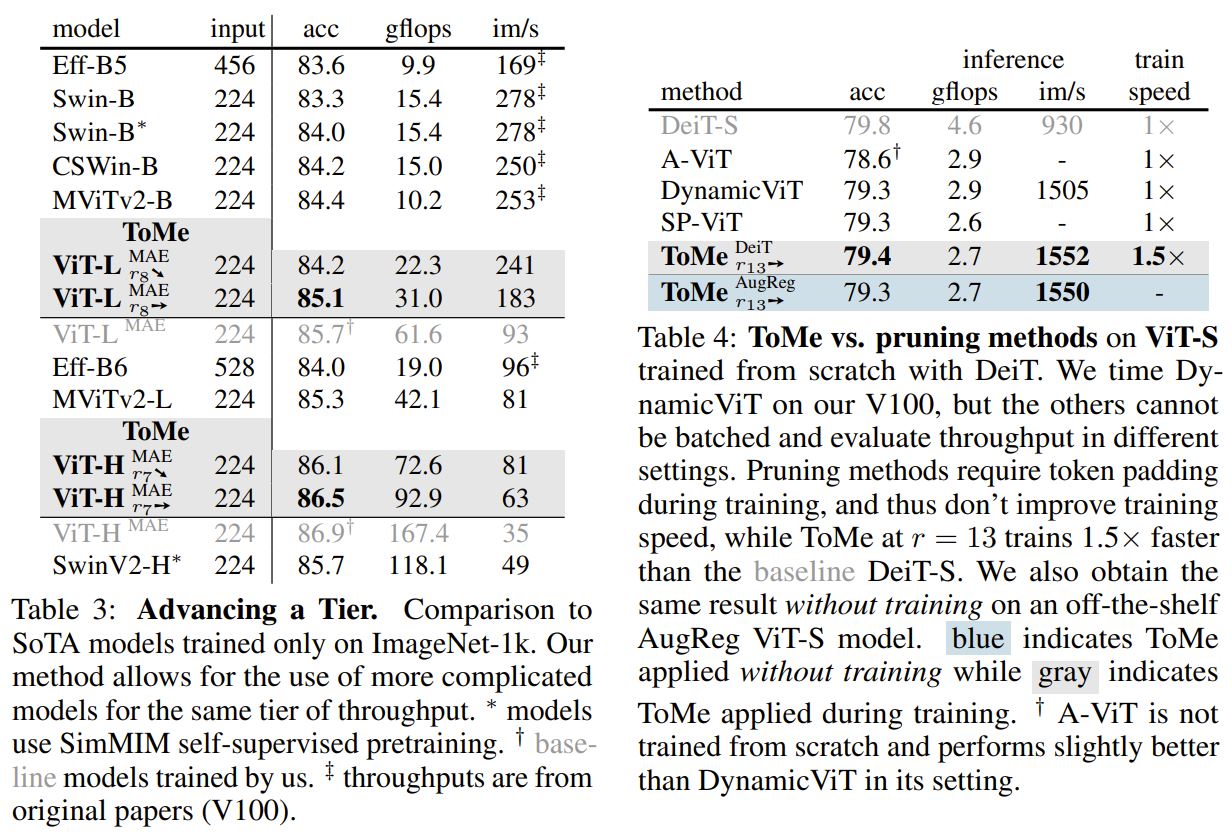

Visualization


Another interesting visualization here.
Conclusions
Token merging (ToMe) has successfully increased the throughput, decreased the training time, and memory usage of ViT models by gradually merging tokens. It is a pure transformer block that can be easily added to existing transformer architectures and even used to create new transformer architectures (high potential in segmentation).