Neighborhood Attention Transformer
Notes
- Code is available on github
- This work was done by the same team that did the Compact Convolutional Transformer (CCT) reviewed in this post
- So they use the same method of Convolutional Tokenization
Highlights
- Similar to Swin Transformer the idea is to reduce the computational cost of the attention mechanism
- The authors introduce the Neighborhood Attention (NA) and the Neighborhood Attention Transformer (NAT)
- With the Neighborhood Attention the attention is only computed on a neighborhood around each token
- This method not only allows to reduce the computational cost of the attention mechanism but also helps to introduce local inductive biases
- The drawback is that it reduces the receptive field
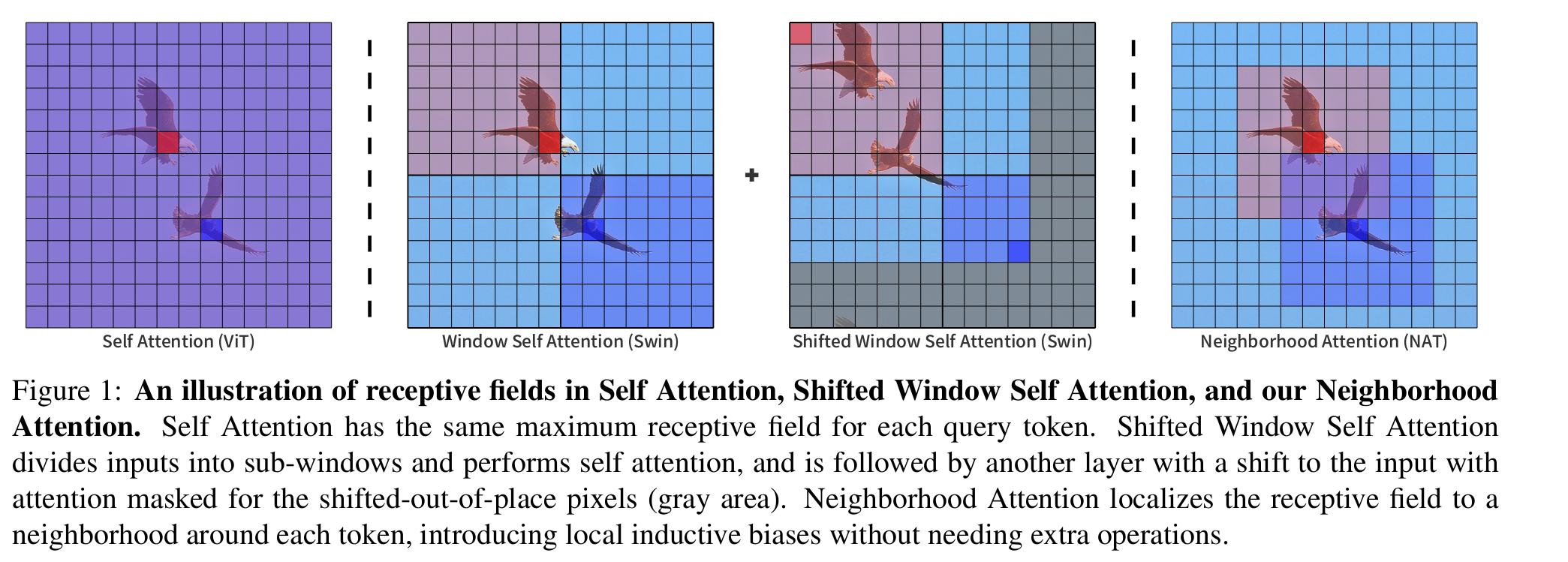
Neighborhood Attention
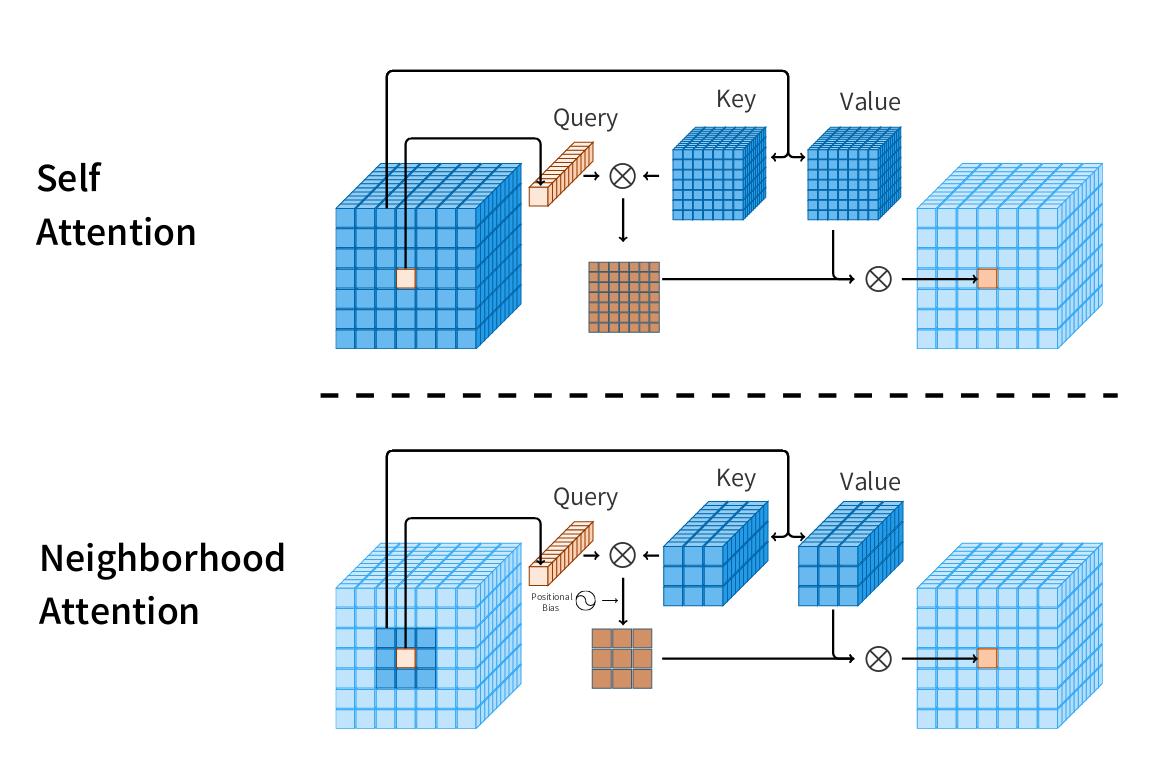
Neighborhood attention on a single pixel \((i, j)\) is defined as follows:
\[NA(X_{i, j}) = softmax(\frac{Q_{i,j}K^T_{\rho(i,j)} + B_{i,j}}{scale})V_{\rho_{(i,j)}}\]where:
-
\(Q, K, V\) are linear projections of \(X\)
-
\(B_{i,j}\) denotes the relative positional bias
-
ρ(i, j) is a fixed-length set of indices of pixels nearest to (i, j). For a neighborhood of size \(L * L\), \(\vert \rho(i,j) \vert = L^2\)
However, if the function ρ maps each pixel to all pixels (\(L²\) is equal to feature map size), this will be equivalent to self attention.
- The complexity of the neighborhood attention is linear with respect to resolution unlike self attention’s.
- The function \(\rho\) which maps a pixel to a set of neighboring pixels is realized with a sliding window.
- For corner pixels that cannot be centered, the neighborhood is expanded to maintain receptive field size. As illustrated in the image below.
![]()
Neighborhood Attention Transformer

-
For the tokenization they use the overlapping convolution method introduced in the Compact Convolutional Transformer
-
The rest of the architecture is a succession of blocks containing a token merging layer to reduce dimension and a standard multi head attention block but with the self attention replaced by the neighborhood attention
-
The token merging layer is also different from the patch merging layer in the Swin Transformer
-
Here the overlapping downsampler consists of a 3x3 convolution with 2x2 strides on the patches
Results
Classification
- Trained on ImageNet-1k (1.2 millions images for training, 1000 classes)
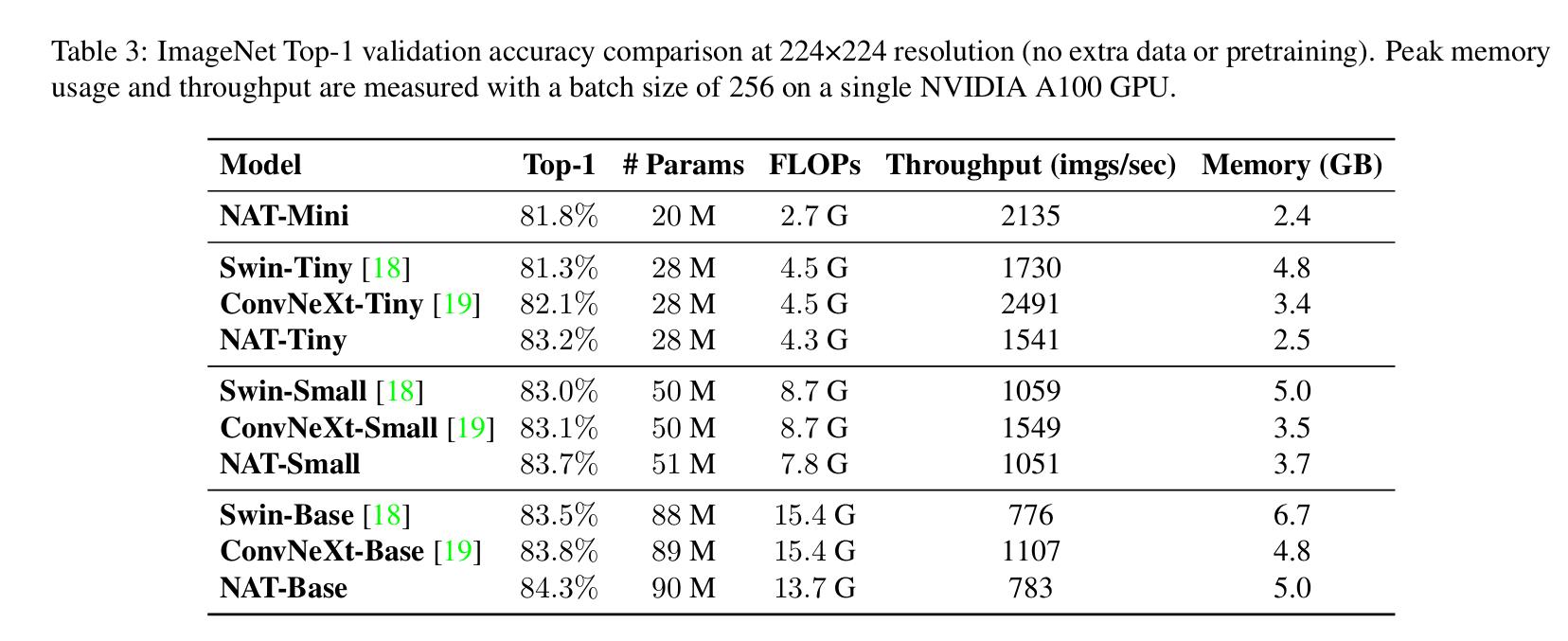
- NAT outperforms Swin Transformers and ConvNeXt
Object Detection
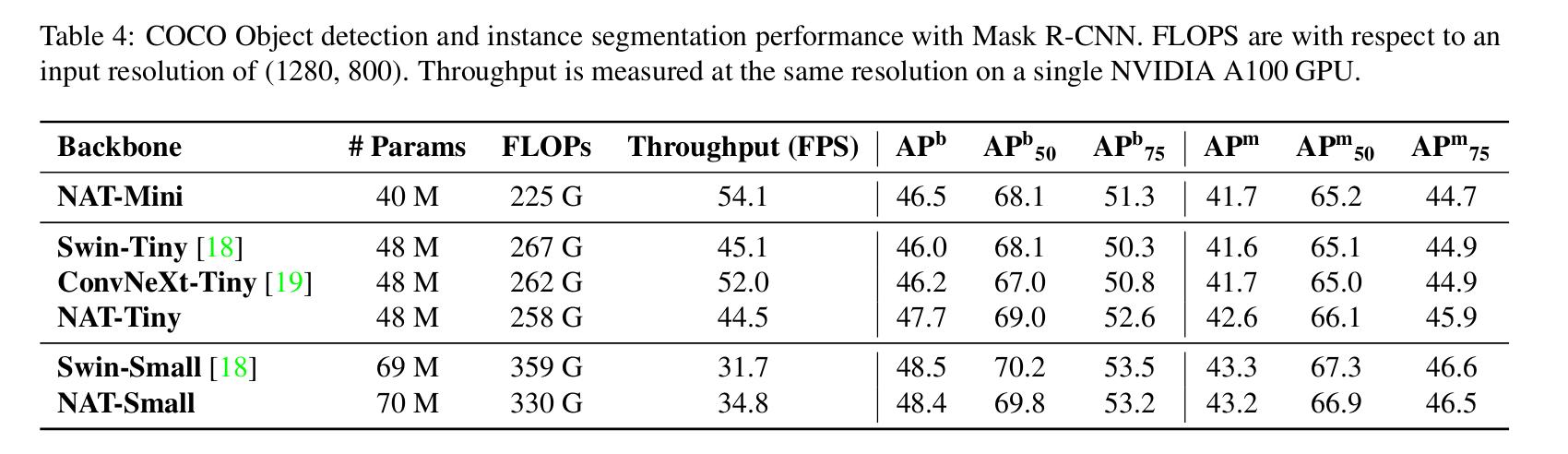
-
Mask R-CNN and Cascade Mask R-CNN with different backbones trained on MS-COCO
Semantic Segmentation
- UPerNet with different backbones trained on ADE20K (20 000 training images)

- NAT performs better than Swin Transformer for the segmentation task
- But NAT fails to beat ConvNeXt, a recent and very efficient convolutional network
Ablation studies
- To attest the efficiency of the Neighborhood Attention, they test their architecture on ImageNet-1k with different kinds of attention
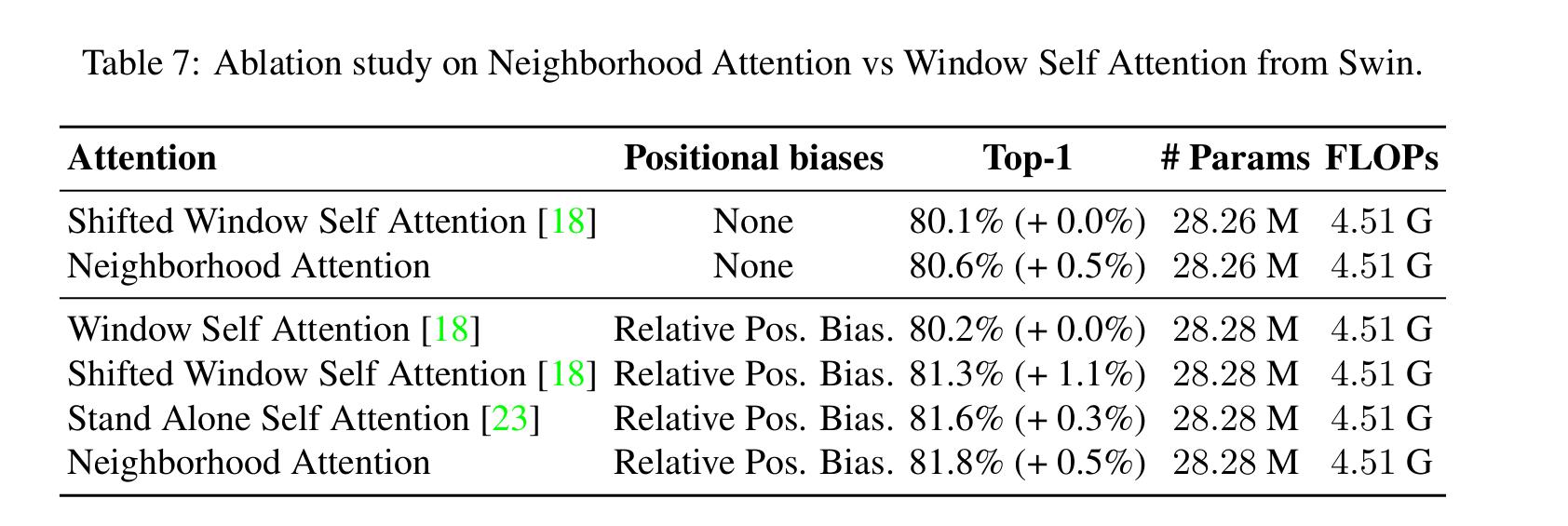
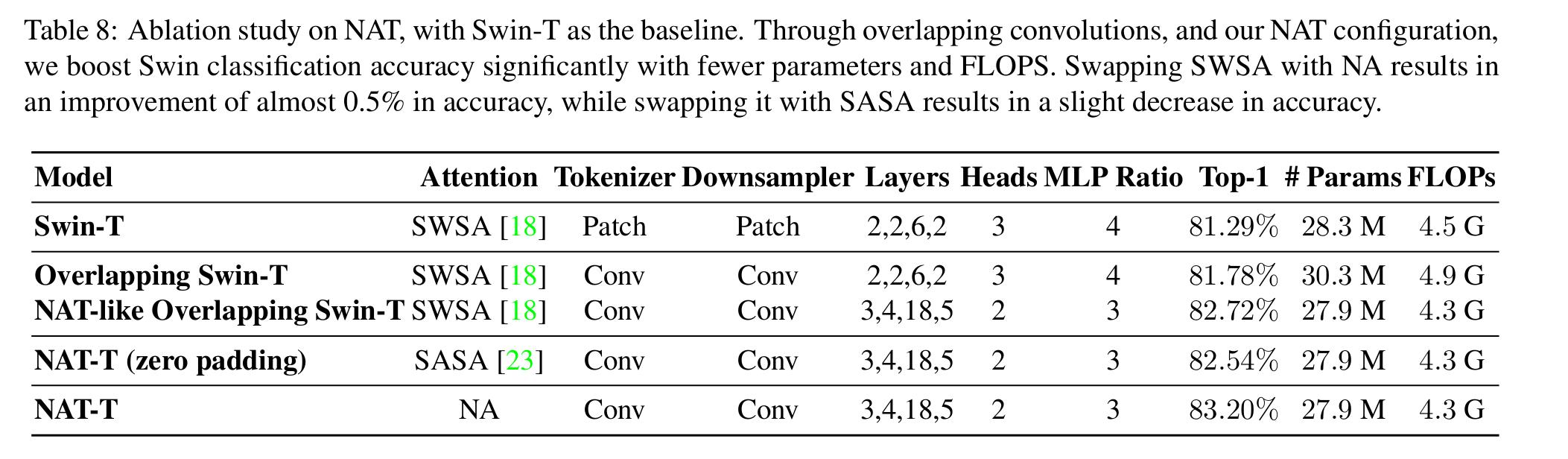
- They also study different merging methods with a Swin Transformer to attests the efficiency of the Overlapping Downsampler
Conclusion
This paper introduces a new and interesting attention mechanism based on the neighborhood of a token. It builds a transformer architecture based on this mechanism that achieves competitive results on different computer visions tasks.