UNesT: Local Spatial Representation Learning with Hierarchical Transformer for Efficient Medical Segmentation
Notes
- Code is available on GitHub in MONAI Model Zoo: https://github.com/Project-MONAI/model-zoo/tree/dev/models.
Highlights
- Introduce a novel hierarchical hybrid 3D U-shape medical segmentation model with Nested Transformers (UNesT).
- Combination of a transformer-based encoder with 3D block aggregation function and a CNN-based decoder with skip connections.
- Validation done on several medical datasets: BTCV, KiTS19, whole brain segmentation dataset, and in-house renal substructure dataset.
Introduction
Limitations of current transformer-based segmentation models:
- limited performance using a small training dataset or when there are many structures in the dataset;
- high model complexity makes transformers less robust in exploring 3D context;
- pretraining on a large dataset is computationally expensive.
To address the potential limitations of transformers, the authors propose the data-efficient UNesT.
Methods
Architecture
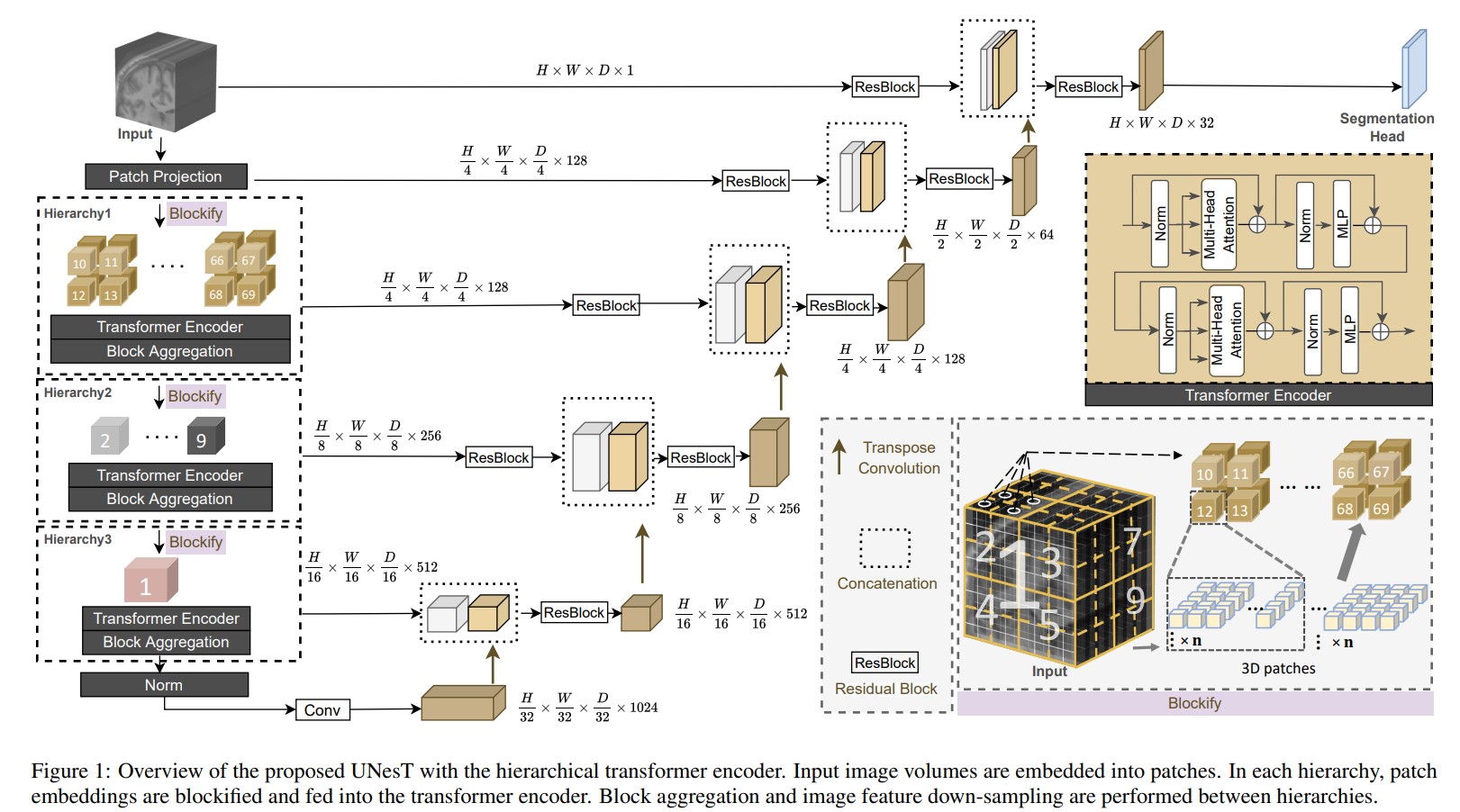
- Given the input subvolume \(\mathcal{X} \in \mathbb{R}^{H \times W \times D \times C}\), the volumetric embedding token has a patch size of \(S_h \times S_w \times S_d \times C\).
- 3D tokens are then projected onto a size of \(\frac{H}{S_h} \times \frac{W}{S_w} \times \frac{D}{S_d} \times C^{'}\) in the patch projection step, where \(C^{'}\) is the embedded dimension.
- For efficient non-local communication, all projected sequences of embeddings are partitioned into blocks (blockify) \(\mathcal{X}\) with a resolution of \(b \times T \times n \times C^{'}\), where \(T\) is the number of blocks at the current hierarchy, \(b\) is the batch size, \(n\) is the total length of sequences, and \(T \times n = \frac{H}{S_h} \times \frac{W}{S_w} \times \frac{D}{S_d}\).
- Each block is fed into sequential transformer separately, which consists of the multi-head self-attention (MSA), multi-layer perceptron (MLP), and layer normalization (LN).
- Learnable positional embeddings are added to sequences for capturing spatial relations before the transformer blocks.
- All transformer blocks at each level of the hierarchy share the same parameters given the input \(\mathcal{X}\).
3D block aggregation:
- Input: \(\mathcal{X} \in \mathbb{R}^{H \times W \times D \times C}\)
- Patch embeddings: \(\frac{H}{S_h} \times \frac{W}{S_w} \times \frac{D}{S_d} \times C^{'}\)
- For \(i = 0,1,2\)
- \(2 \times 2 \times 2\) conv. pooling if \(i > 0\)
- Blockify: \(b \times T_i \times n \times C^{'}_i\), where \(T_i = 64, 8, 1\) and \(C^{'}_i = 128, 256, 512\). Since \(2 \times 2 \times 2\) pooling is done for \(i > 0\) and \(n\) remains the same, \(T_i\) is divided by 8.
- Transformer encoder: \(b \times T_i \times n \times C^{'}_i\)
- Deblockify: \(\frac{H}{2^i \times S_h} \times \frac{W}{2^i \times S_w} \times \frac{D}{2^i \times S_d} \times C^{'}_i\)
Decoder:
- To better capture localized information and further reduce the effects of lacking inductive bias in transformers, CNN-based decoder is used.
- Skip connections from transformer encoders are fed to residual blocks and then concatenated with the decoder before the up-convolution process.
More interpretable architecture overview:

Training strategy: All experiments are implemented in PyTorch and MONAI. During the training, an input patch size of \(96 \times 96 \times 96\) and a cosine warm-up scheduler of 500 steps are used.
Benchmarking datasets
The authors benchmarked UNesT on 4 datasets: BTCV, KiTS19, Whole brain segmentation dataset (133 classes), and in-house renal substructure dataset. Whole brain segmentation dataset is a combination of multiple open access brain dataset with either manual or pseudo annotations.
Results
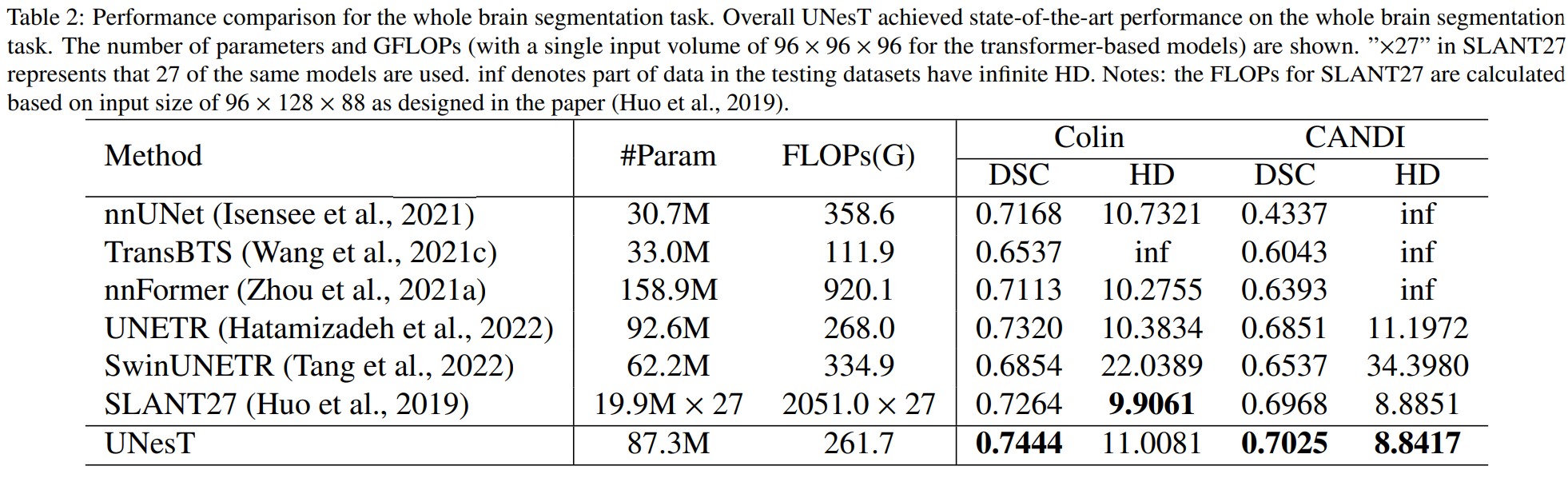
Whole brain segmentation dataset
All models are pretrained with 4859 auxiliary pseudo labels and are fine-tuned with 50 manually traced labels. 5-fold cross validation is done for all models and the ensembled models are used for inference.

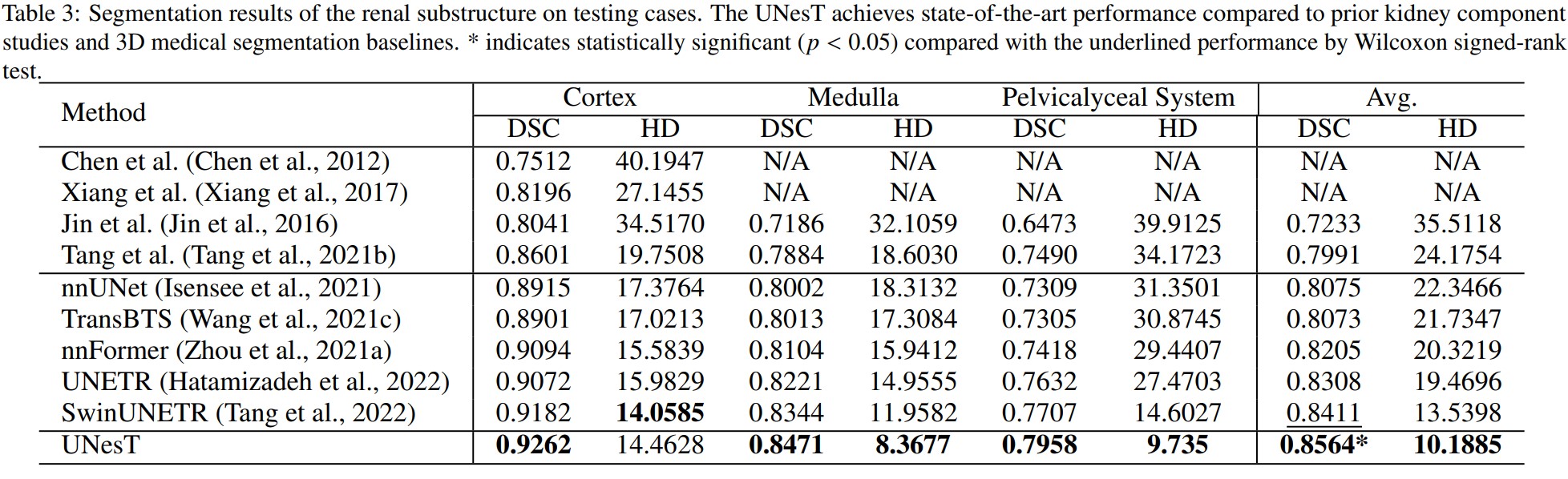
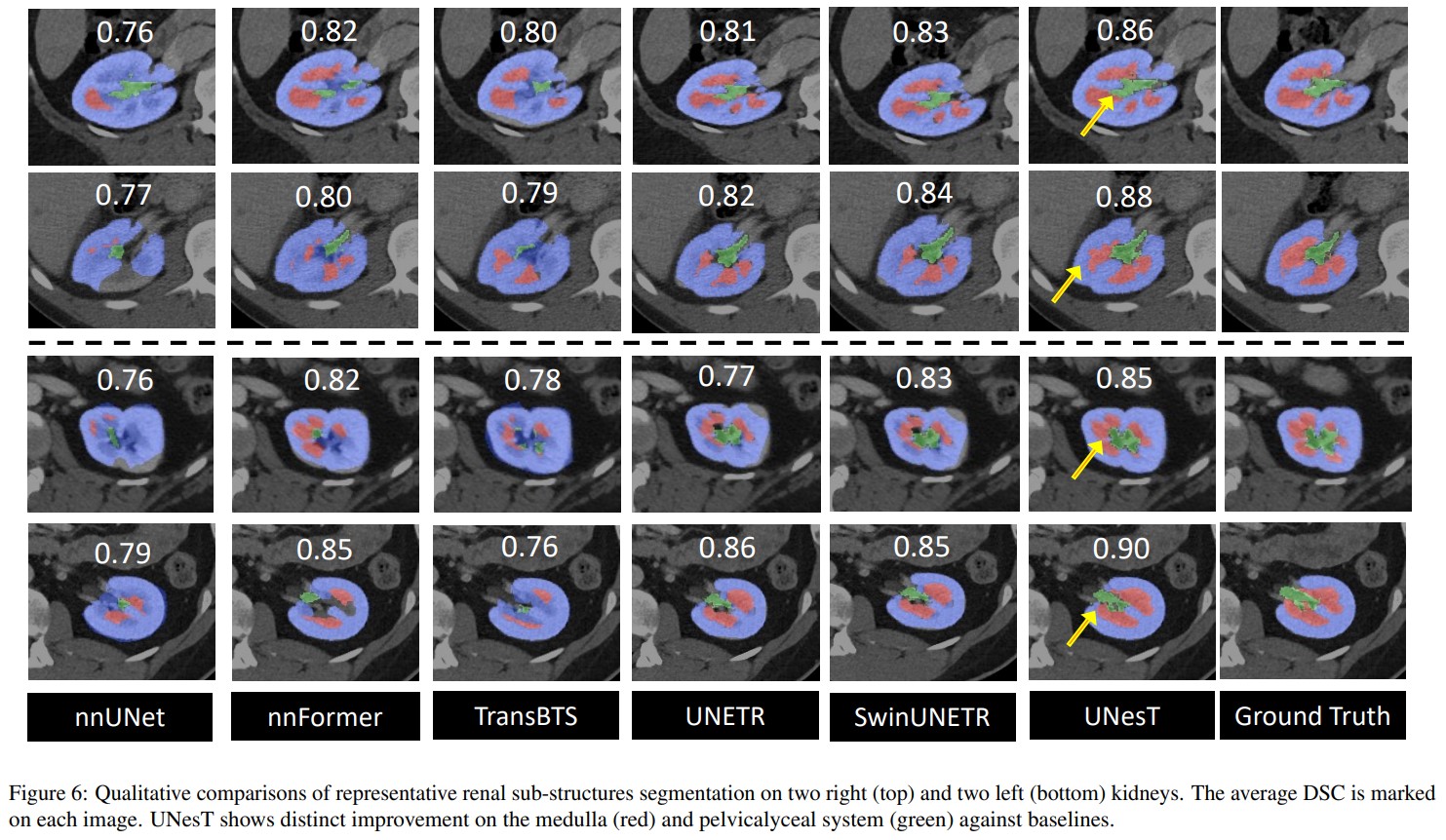
Renal substructure dataset
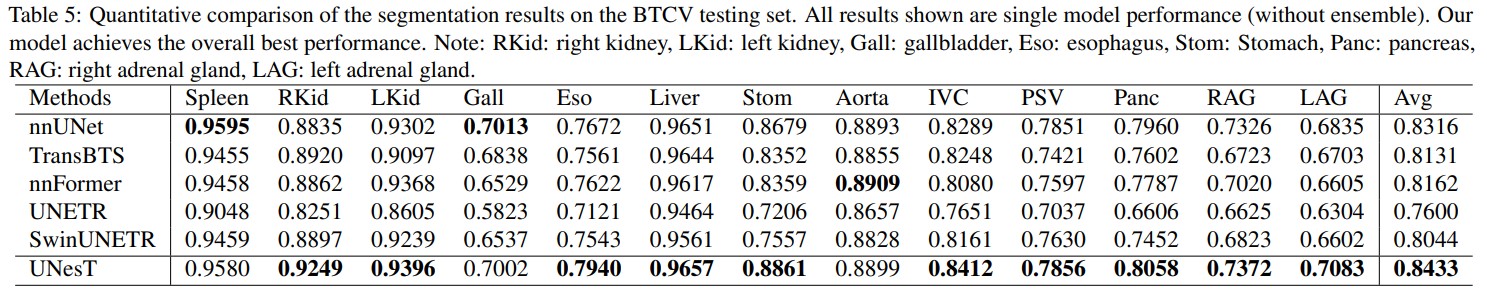
BCTV dataset
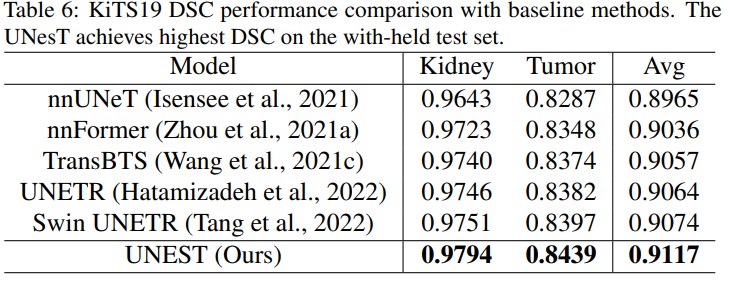
KiTS19 dataset
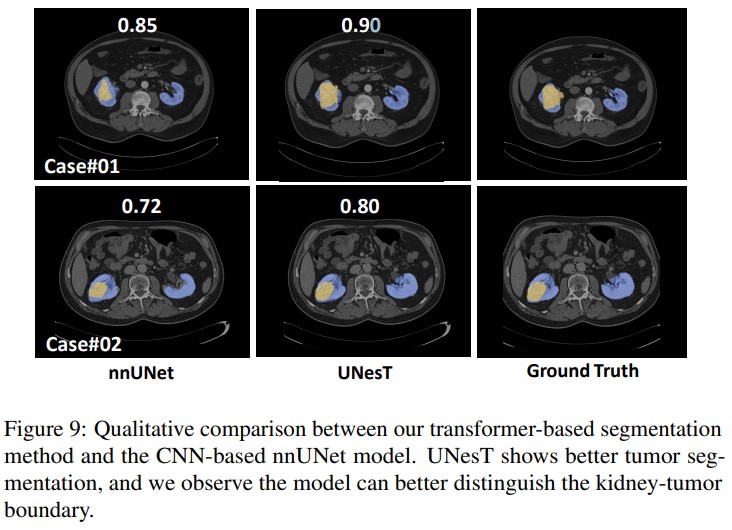
Ablation study
-
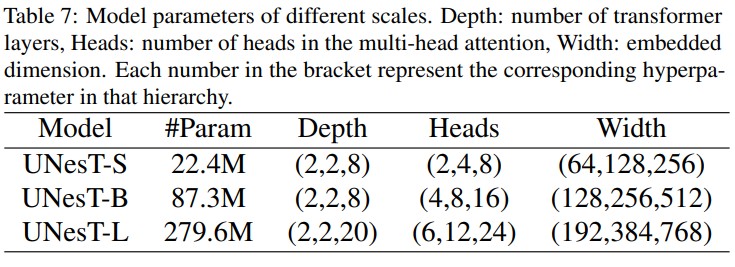
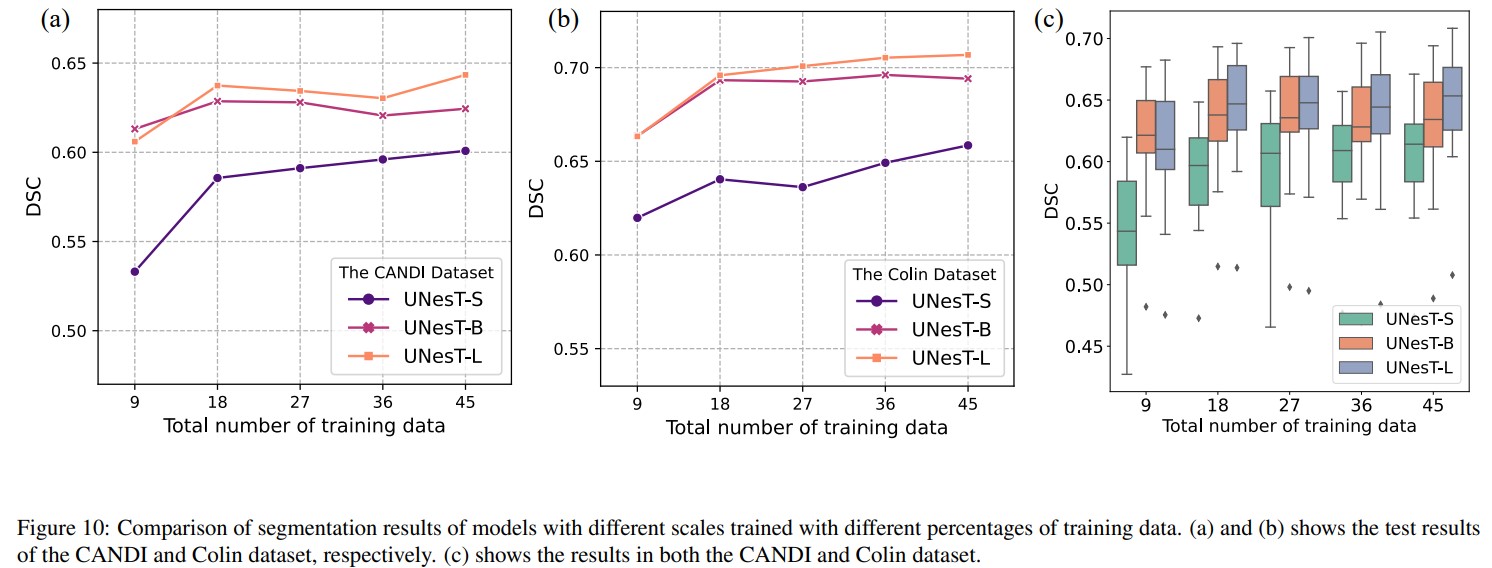
The authors introduce 3 UNesT models with different scales: small, base, and large.
-
They prove that the base and large models can scale well when there is more data.
-
When trained on same number of data (20%), UNesT-L > UNesT-B > UNesT-S.

-
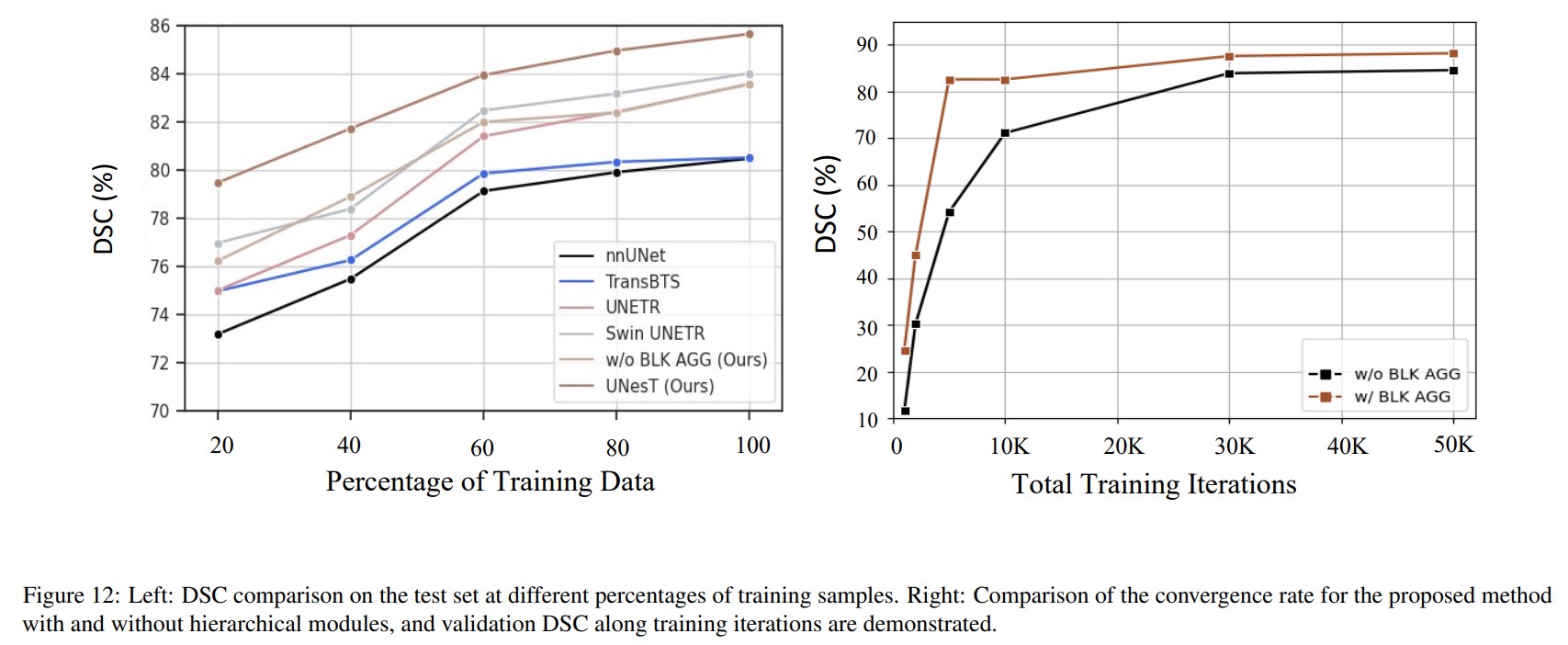
They also compare the performance of different models trained with different percentages of training data and prove that hierarchical architecture design with 3D block aggregation provide significant improvement for medical image segmentation. Therefore, 3D aggregation modules > shifted windows in Swin Transformer.
-
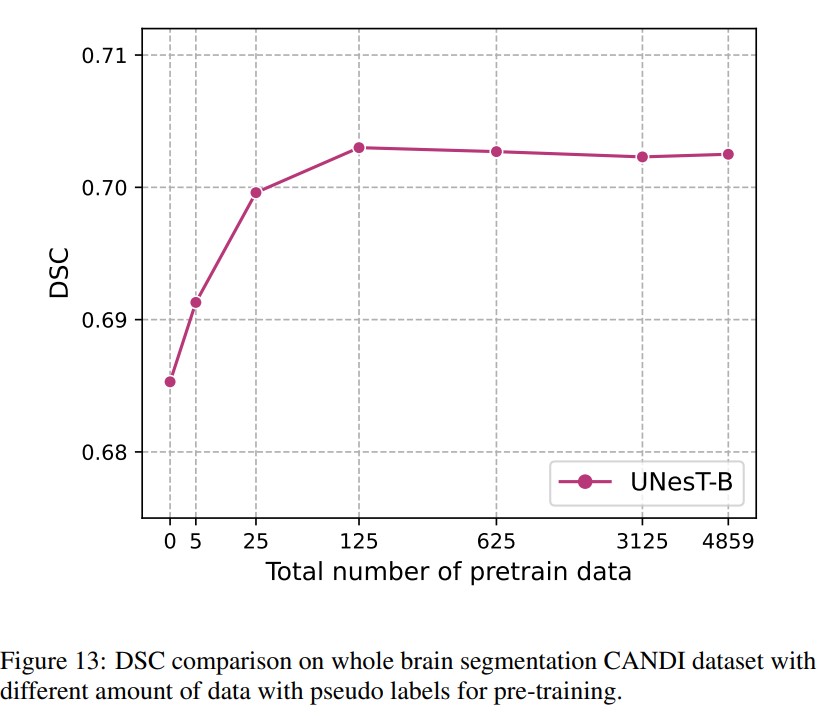
They show that UNesT does not require many pre-training data to achieve a performance gain.
Conclusions
The authors proposed a novel hierarchical transformer-based medical image segmentation approach (UNesT) with 3D block aggregation module to achieve local communication. This approach efficiently combined global and local information, and successfully solved two critical problems of transformer-based segmentation models: lack of local positional information resulting in sub-optimal performance when handling numerous tissue classes, and the need of large training datasets to achieve good performance.