Adversarial Discriminative Domain Adaptation
Related Talk
For an overview of domain adaptation, especially with regards to medical imaging, you can also listen to this keynote given by Ben Glocker at the Domain Adaptation and Representation Transfer (DART) workshop at MICCAI 2020: https://www.youtube.com/watch?v=u6jcpPfWtYE
What is Domain Adaptation ?
A domain can be seen as the underlying distribution that was sampled to obtain a given dataset. For instance let us consider that \(\mathcal{X}\) is the space in which the samples live and \(\mathcal{Y}\) the space of their annotations/labels. A domain is the joint distribution \(p(x,y)\) on \(\mathcal{X} \times \mathcal{Y}\) that you have to sample to produce a dataset. By sampling \(p(x,y)\) one obtain a (sample, label) pair, i.e., \(x,y \sim p(x,y)\). And sampling \(n\) times from the domain yields a dataset composed of \(n\) (sample, label) pairs \(\{ x_{i}, y_{i} \}_{i=1}^{n}\).
Domain Adaptation (DA) is part of the transfer learning1,2 research field. The later aims at transferring capabilities of a trained (deep) model on new tasks (e.g., classification \(\rightarrow\) segmentation) and/or on new domains (e.g., classification \(\rightarrow\) segmentation). Domain Adaptation (DA) is restricted to doing the transfer on a new target domain, but still performing the same task as trained on the source domain. A motivation for DA is that one can reuse a model trained on a source domain and apply it on a target domain, even if the target domain is not annotated.

Figure 0: Illustration of the adversarial domain adaptation concept : they learn a discriminative mapping of target images to the source feature space (target encoder) by fooling a domain discriminator that tries to distinguish the encoded target images from source examples.
To improve generalization performance on an unlabeled test set, the authors proposed a discriminative unsupervised domain adaptation method to reduce the difference between the training (=source) domain and the test (=target) domain.
Claimed contributions :
- a general framework for adversarial adaptation.
- the ADDA method :
- discriminative modeling
- untied weight sharing
- GAN loss
- SOTA results on adaptation for digit classification (MNIST3, USPS, SVHN4), and cross-modality adaptation (NYUD5)
Generalized adversarial framework
Let’s introduce their first contribution by citing directly the paper :
In unsupervised adaptation, we assume access to source images \(X_s\) and labels \(Y_s\) drawn from a source domain distribution \(p_s(x, y)\), as well as target images \(X_t\) drawn from a target distribution \(p_t(x, y)\), where there are no label observations. Our goal is to learn a target representation, \(M_t\) and classifier \(C_t\) that can correctly classify target images into one of \(K\) categories at test time, despite the lack of in domain annotations.
To compare the adversarial methods that try to achieve such an adaptation (i.e., training an encoder \(M_t\) and a classifier \(C_t\) so that \(C_t(M_t(x_t))\) is a correct prediction as much as possible), the authors propose a generalized adversarial framework which requires to choose three elements :
- the base model (disciminative or generative)
- the weight sharing strategy (shared or unshared)
- the adversarial loss (confusion, minimax, GAN, …)
Here is an illustration of this generalized adversarial framework:
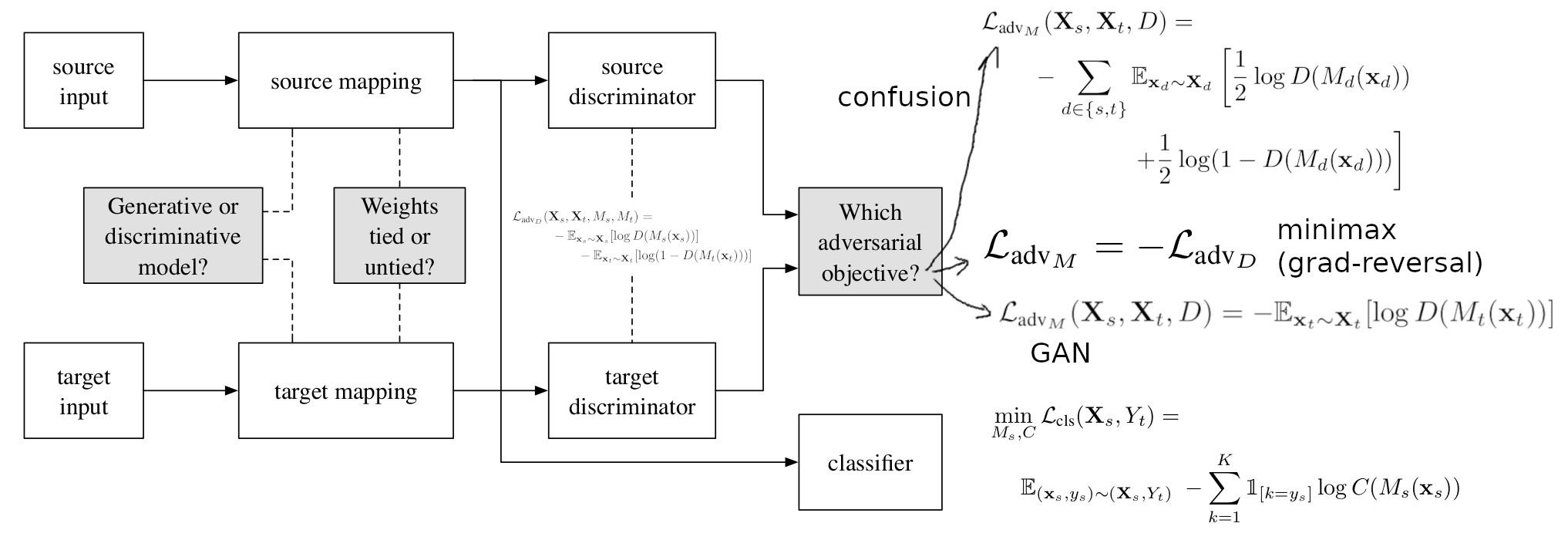
Figure 1: Proposed general adversarial framework
Adversarial Discriminative Domain Adaptation (ADDA)
Here are the characteristics of the method they propose :
- base model : discriminative
- weight sharing strategy : unshared
- adversarial loss : GAN
For the choice of a discriminative model, they argue that :
modeling the image distributions (input domain = full scale images) is not strictly necessary to achieve domain adaptation, as long as the latent feature space is domain invariant.
For the choice of an independent source and target mappings (untying the weights), they argue that :
This is a more flexible learing paradigm as it allows more domain specific feature extraction to be learned. However, note that the target domain has no label access, and thus without weight sharing a target model may quickly learn a degenerate solution if we do not take care with proper initialization and training procedures. Therefore, we use the pre-trained source model as an intitialization for the target representation space and fix the source model during adversarial training.
For the choice of the adversarial loss, they argue that :
we are effectively learning an asymmetric mapping, in which we modify the target model so as to match the source distribution. This is most similar to the original generative adversarial learning setting, where a generated space is updated until it is indistinguishable with a fixed real space. Therefore, we choose the inverted label GAN loss described in the previous section.
Here is an illustration of the proposed ADDA method :

Figure 2: Pipeline of the proposed ADDA method: first they pre-train a source encoder CNN using labeled source image examples. Next, they perform adversarial adaptation by learning a target encoder CNN such that a discriminator that sees encoded source and target examples cannot reliably predict their domain label. During testing, target images are mapped with the target encoder to the shared feature space and classified by the source classifier. Dashed lines indicate fixed network parameters
Experiments
The first task that on which the adaptation is evaluated consists of classifying digits (10 classes). There are three datasets (MNIST, USPS, SVHN) and the adaptation is done in the following :
- MNIST \(\rightarrow\) USPS
- USPS \(\rightarrow\) MNIST
- SVHN \(\rightarrow\) MNIST

Figure 3: illustration of some dataset samples in the task of digit classification : MNIST, USPS, and SVHN datasets are used
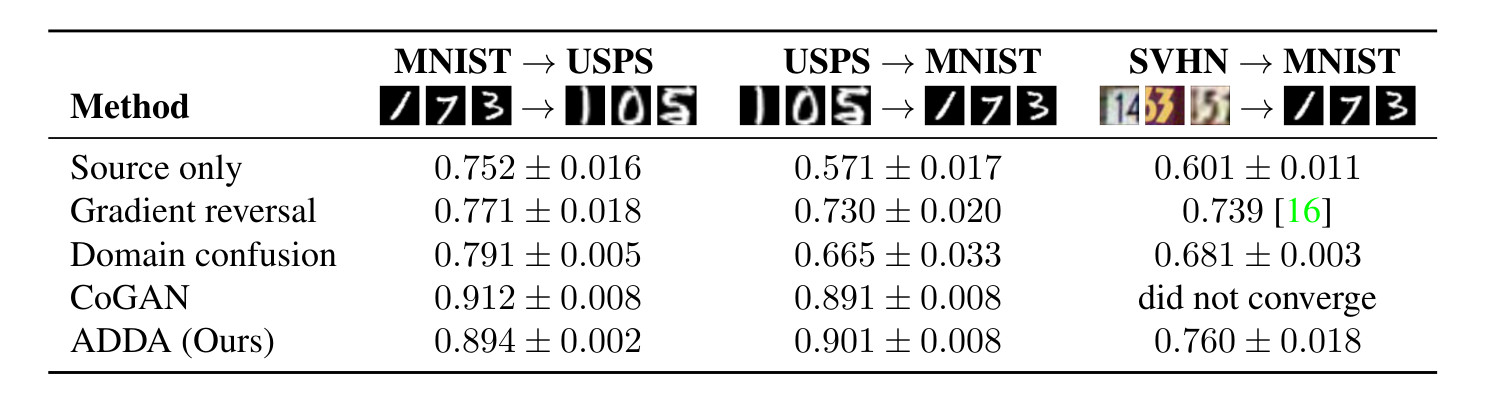
Figure 4: Experimental results on unsupervised adaptation among MNIST, USPS, and SVHN
The second task is still classification (on objects this time) but with a cross-modality (between RGB and depth modalities) adaptation additional difficulty (NYU depth dataset):
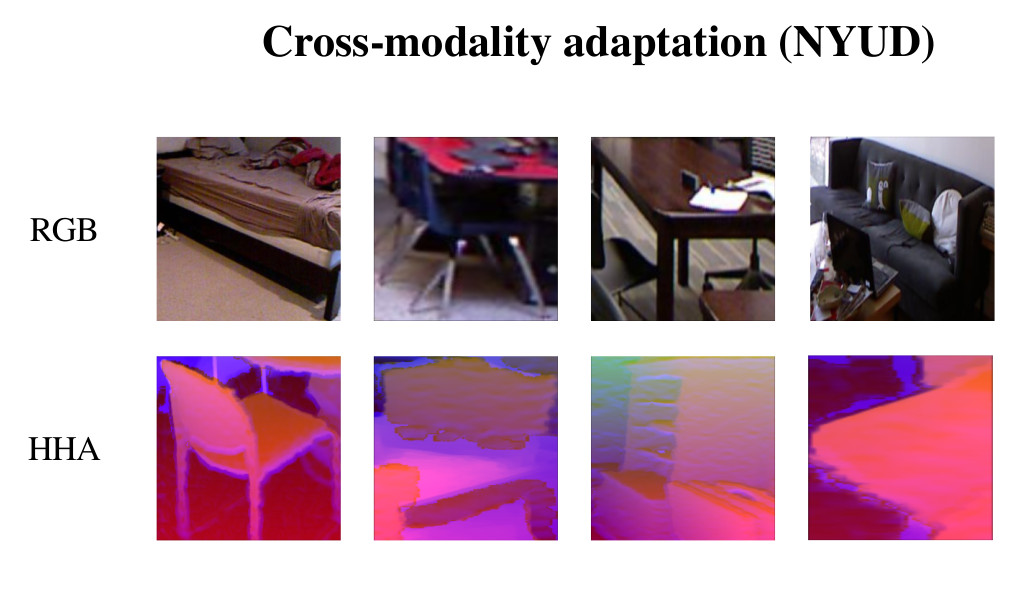
Figure 5: illustration of the RGB and depth modalities from the NYU depth dataset
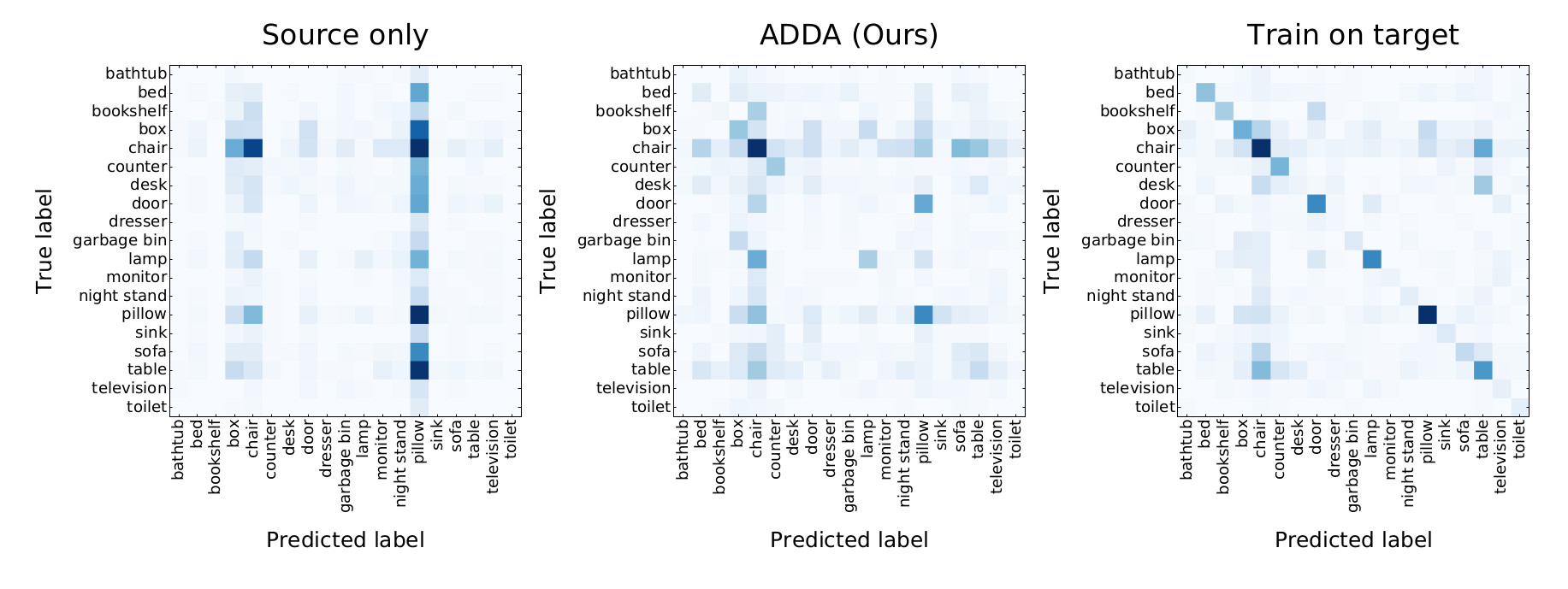
Figure 5: Confusion matrices for source only, ADDA, and oracle supervised target models on the NYUD RGB to depth adaptation experiment.
Conclusion
The authors proposed a unified framework for adversarial unsupervised domain adaptation techniques.
They proposed an adaptation method (ADDA) that uses a discriminative model (discrimination task performed in the latent space), an independent-weight strategy for source and domain encoders and a GAN inspired adversarial loss.
They evaluated their unsupervised adaptation method across four domain shifts for classification task :
- MNIST \(\rightarrow\) USPS
- USPS \(\rightarrow\) MNIST
- SVHN \(\rightarrow\) MNIST
- RGB \(\rightarrow\) depth map (NYU depth dataset)
References
-
J. Wang and Y. Chen, Introduction to Transfer Learning: Algorithms and Practice. in Machine Learning: Foundations, Methodologies, and Applications. Singapore: Springer Nature, 2023. doi: 10.1007/978-981-19-7584-4. ↩
-
F. Zhuang et al., “A Comprehensive Survey on Transfer Learning,” Proceedings of the IEEE, vol. 109, no. 1, pp. 43–76, Jan. 2021, doi: 10.1109/JPROC.2020.3004555. ↩
-
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, November 1998 ↩
-
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y. Ng. Reading digits in natural images with unsupervised feature learning. In NIPS Workshop on Deep Learning and Unsupervised Feature Learning 2011, 2011. ↩
-
Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and Rob Fergus. Indoor segmentation and support inference from rgbd images. In European Conference on Computer Vision (ECCV), 2012 ↩