CLIP : Learning Transferable Visual Models From Natural Language Supervision
Introduction
- CLIP is a model that predicts image-text similarity
- Example : given an image and \(N\) text descriptions, it can rank them by similarity to the image.

Highlights
- Is trained with a simple pre-training task
- Use data abundantly available on the internet
- Can be used in many other visual tasks with a zero-shot approach
- Scaling up the data is sufficient to achieve competitive performance
Approach
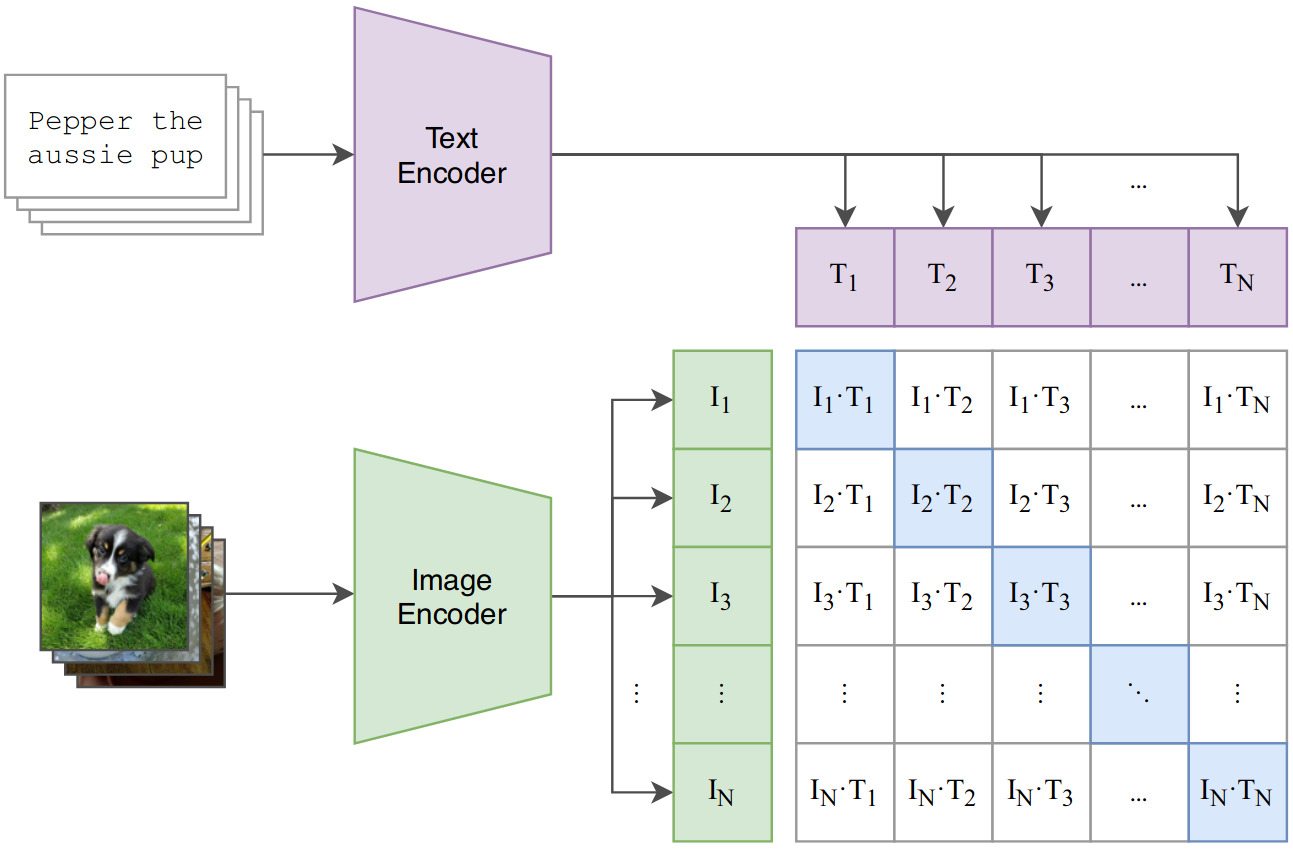
Warning : the approach is pretty simple and not new, but CLIP scaled it up to show its potential
- Given a batch of \(N\) image and text, CLIP is trained to predict the ground-truth (image, text) pairs among the \(N × N\) possible pairs
- Two encoders : text encoder and image encoder
- Linear projection into a multi-modal embedding space
- Goals :
- Maximize cosine similarity of real pairs
- Minimize cosine similarity of incorrect pairs
- Loss : symmetric cross-entropy
- Temperature parameter is trainable

Dataset
- Already available datasets are either too small or without good enough descriptions
- Construct on a new dataset with 400 millions (image, text) pairs : WebImageText (WIT)
- Private dataset
Models
- Two models for the image encoder : ResNet50 and ViT
- Text encoder :
- Transformer architecture : 63M-parameter 12-layer 512-wide model with 8 attention head
- 49,152 vocab size, sequence length capped at 76
- The activations of the highest layer of the transformer at the [EOS] token are treated as the feature representation of the text
Training
- Adam optimizer, 32 epochs
- Decay of learning rate with cosine scheduler
- Huge batch size of 32 768
- Training time :
- ResNet50x64 : 18 days on 592 V100 GPUs
- ViT-L/14 : 12 days on 256 V100 GPUs
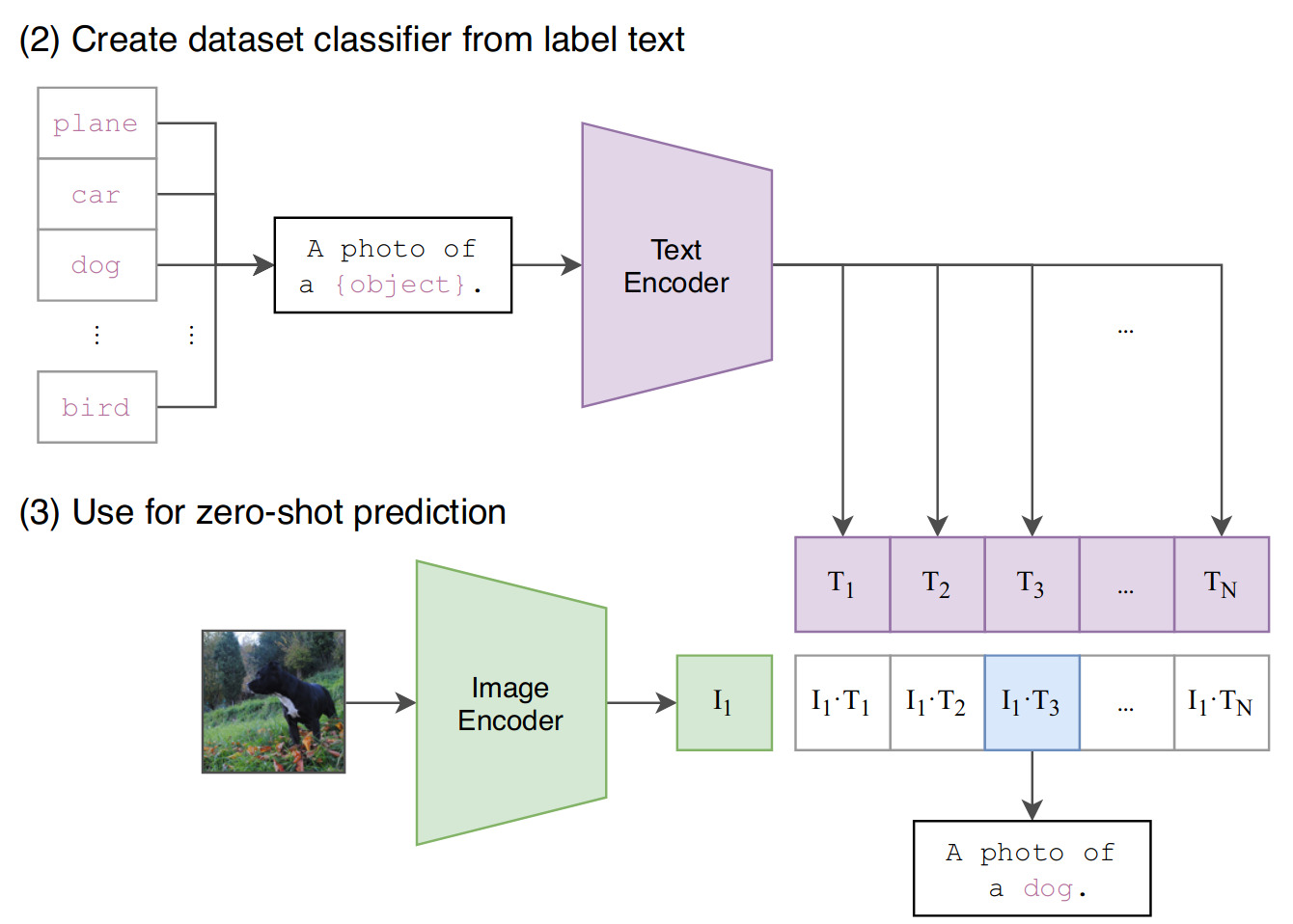
Using CLIP for zero-shot image classification
- Convert the labels into text descriptions
- Example : A photo of a {label}
- Prompt ensembling : A photo of a big {label}, A photo of a small {label}, etc..
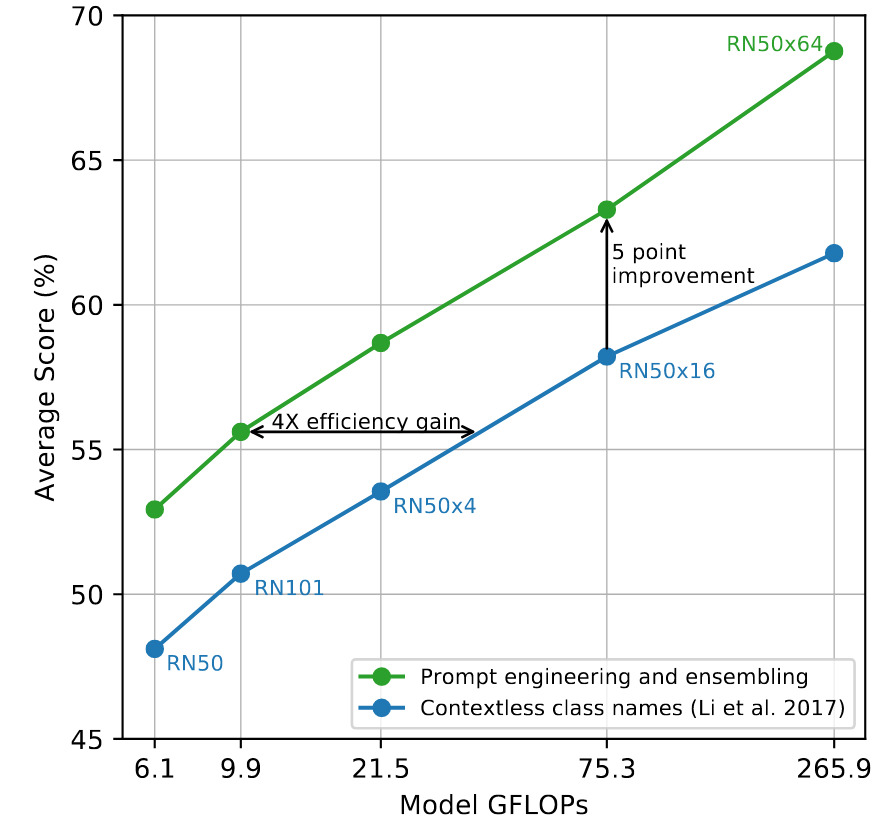
(Much) Better than previous method
Here CLIP is a ViT-L/14 at 336x336

Prompt engineering and ensembling help a lot
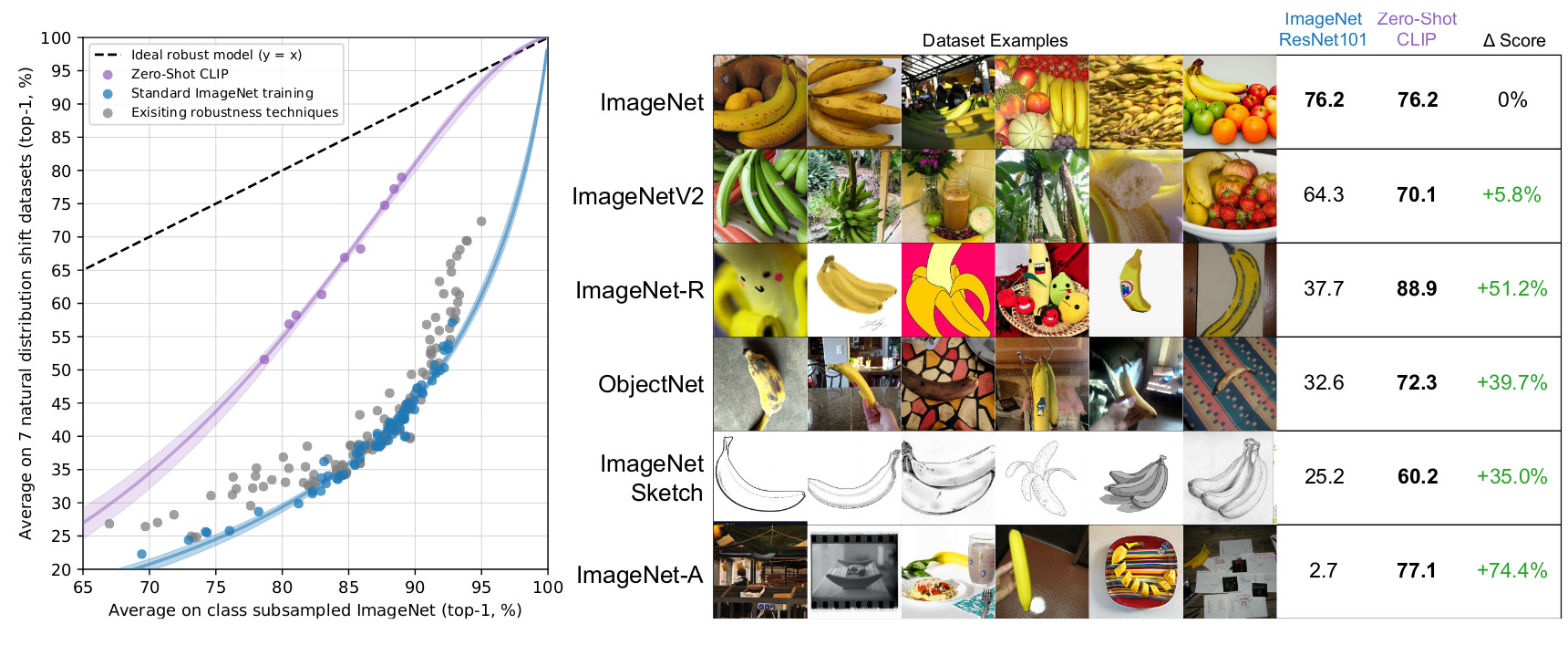
Zero-shot results on 27 datasets

Can be better than few-shot linear probing

CLIP models are more robust to natural distribution shifts

Limitations
- Only competitive with a linear classifier on top of ResNet50 features…
- Far behind state-of-the-art in many tasks
- Authors estimate a “1000x increase in compute” is necessary to reach state-of-the-art in zero-shot using CLIP
- Poor performance on several fine-grained tasks (models of cars, species of flowers, …) and more abstract tasks (e.g. counting)
- Poor performance on truly OOD data (e.g. 88% on MNIST)
- No caption generation, only caption retrieval
- Unfiltered and uncurated image-text pairs, resulting in many social biases
This is a 2021 paper, where is CLIP in 2023 ?
- Besides its zero-shot capabilities in image classifcation CLIP has become a building block of many works (e.g. Stable Diffusion, SAM)
- Because the WIT dataset is not available, OpenCLIP is an open-source implementation of CLIP :
- 3 datasets : LAION-400M, LAION-2B, DataComp-1B
- Better performance than original CLIP (ViT-G/14 on LAION-2B, 80.1% on ImageNet)
- Also releases CLIP with ConvNext (ConvNext-XXLarge 256x256, 79.1% on ImageNet)
- Many variations with smaller models (ViT-B, ConvNext-Base)