SAM 2: Segment Anything in Images and Videos
Highlights
- SAM 2 is a foundation model for video segmentation from prompts, namely points, bounding boxes and masks.
- It achieves state-of-the-art performance on many zero-shot image and video tasks, including interactive video object segmentation and semi-supervised video object segmentation.
- Code and pretrained weights are available on the official Git repo and demo is possible on SAM 2 web page.
Introduction
In 2023, META introduced Segment Anything Model (SAM), a foundation model for image segmentation, promptable with points, bounding boxes, masks and text. Please see this post for further details about SAM paper. Since, the model has been improved and adapted/finetuned for specific domains, such as medical imaging.
In this paper, the authors pursue SAM’s original work by proposing a new model: SAM 2, a unified model for image and video segmentation from prompts. More specifically, their aim is to allow the user to prompt any frame of a video. The prompts can be positive or negative points, bounding boxes or masks. The model should receive initial (single or multiple) prompts and be able to propagate them across all the video frames. If the user then provides other prompts, on any frame of the video, the model should be able to immediately refine the masklets thoughtout the video. Figure 1 illustates an example of this promptable video segmentation task.
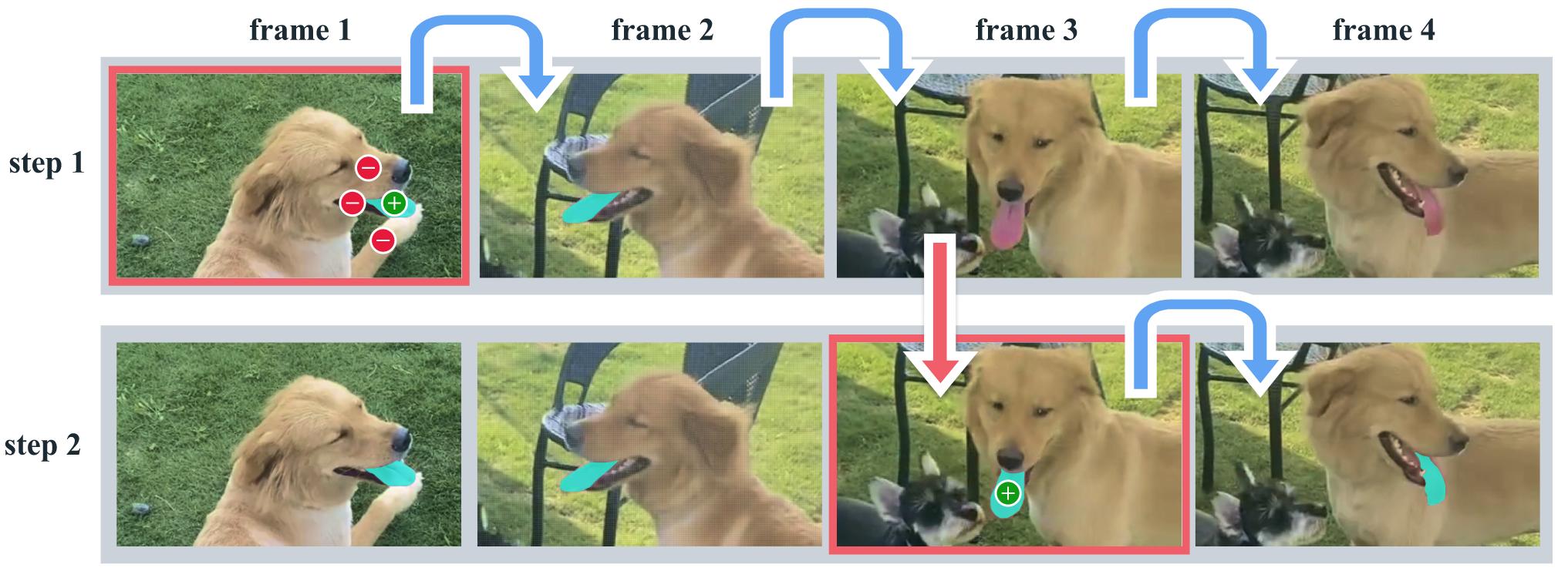
Figure 1. Example of interactive task with SAM 2.
As the in SAM original paper, the work of the authors is composed of two main parts:
- A model, SAM 2, which produces segmentation masks of the object of interest both on single frames (as SAM) and across video frames.
- A dataset, built with a data engine comparable to SAM’s, that is with back-and-forth iterations between automatic models and manual annotators. The final Segmentation Anything Video (SA-V) dataset contains 35.5 millions masks across 50.9K videos, which is around 50 times more than any existing video segmentation dataset.
Both aspects will be presented in the next sections.
Segment Anything Model 2
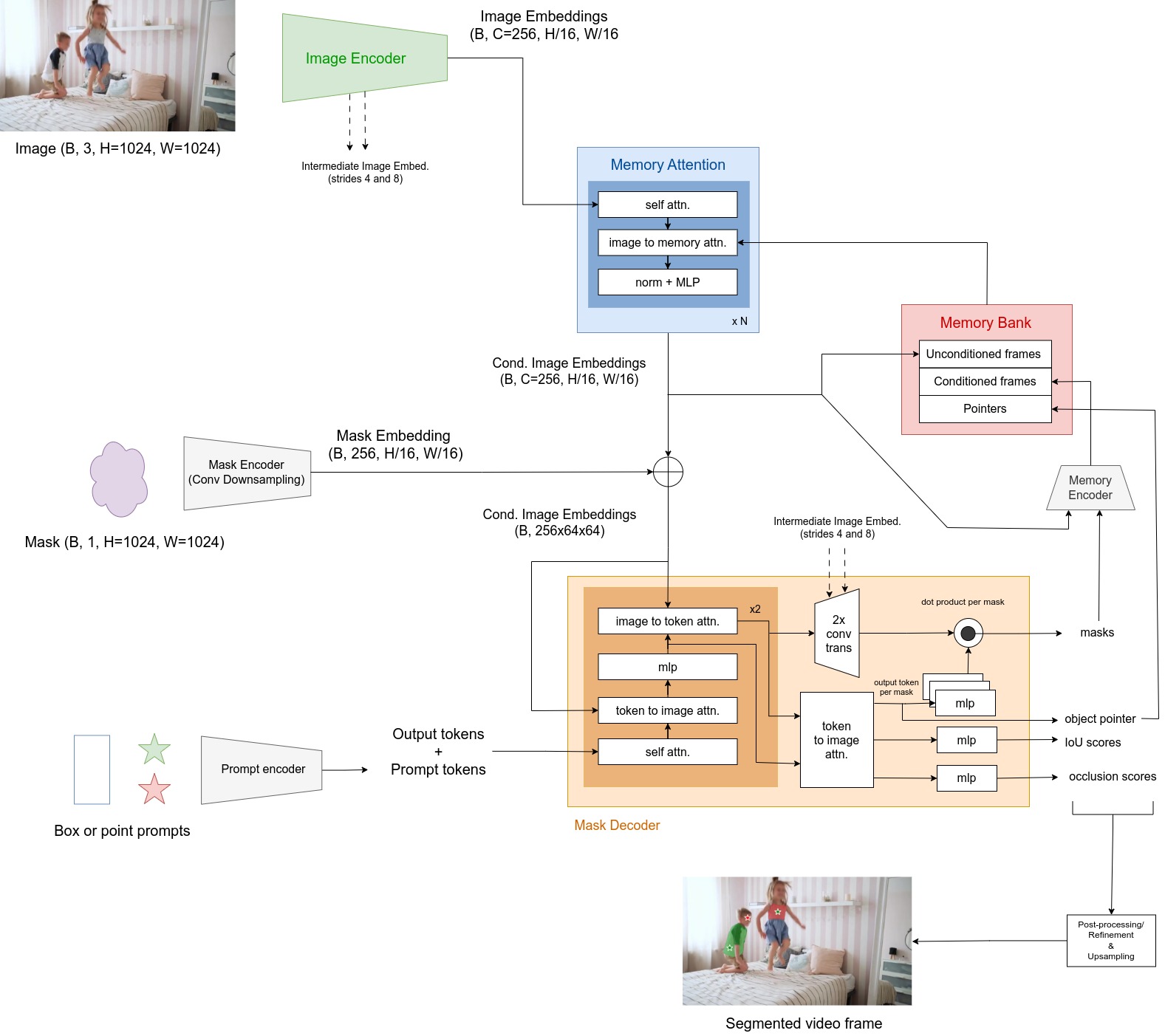
Figure 2. Overview of SAM 2.
SAM 2 is broadly similar to SAM with two major changes: a more recent and powerful image encoder, and a memory mechanism for ensuring consistency between segmented masks across frames. As a reminder, SAM is composed of a ViT image encoder, a prompt encoder and a lightweight decoder for producing the output masks. A consequence of such an asymetric model is that encoding an input image is relatively long, but adjusting to different prompts is then very fast. This property is also found in SAM 2. Figure 2 details all the components of the model.
Image encoder
They authors used a Hiera1, a recent hierarchical vision transformer using only standard ViT blocks and global attention (except for the first two stages) and designed to be more efficient than windowed SwinViT or MViT. The image encoder is pretrained with Masked Auto-Encoder procedure. The final frame embeddings are obtained by fusing the features from stages 3 and 4 of the Hiera image encoder. Contrary to SAM, intermediate stage features are also kept and later added to the upsampling layers in the mask decoder to help produce high-resolution segmentation details.
The image encoder is run only once over all the images to produce unconditioned image tokens representing each frame.
Memory attention
The role of memory attention is to condition frame features on the past feature frames and predictions as well as on any new prompts. It is composed of several transformer blocks in which there is self-attention between the image embeddings of the current frame, and cross-attention to tokens of the objects in the memory bank, meaning prompted or unprompted frames and objets pointers (see relevant section for further details).
Prompt encoder
Prompt encoders are similar to SAM’s : sparse prompts, i.e. points and bounding boxes, are represented by positional encodings summed with learnt embeddings for each prompt type and dense prompts, i.e. masks, are embedded using (downsampling) convolutions and summed with the conditioned frame embeddings.
Mask decoder
The decoder architecture is again quite similar to that of SAM. It takes as input the conditioned frame embeddings (with potential mask encoded embeddings) on one hand, and sparse prompts tokens, concatenated with tokens used for the output, on the other hand. Each decoder block is composed of three main blocks : a block of self-attention between prompt+ouput tokens, followed by two blocks of cross-attention, the first one from prompt+output tokens to image tokens and the second one from image tokens to prompt+output tokens.
N.B: X to Y cross-attention means that X is query and Y is key and value in the attention layer.
The model produces multiple outputs from the resulting tokens:
- The tokens are upsampled with convolutions and summed with stages 1 and 2 frame features from Hiera image encoder. They are multiplied with the output tokens (after passing through 3 MLP layers) to produce low-resolution masks (at a resolution 4x lower than input image).
- The output tokens are also used to produce what are called object pointers, which are lightweight vectors to encode high-level semantic information of the object to segment.
- As in SAM, there could be ambiguity on the mask to predict, as an object can have several subparts that are also segmented. For this reason, the model produces multiple output masks (3 in general) and predicts the IoU scores between the ground truth and each mask.
- Finally, a specific challenge of video segmentation is that objects of interest can disappear from the image, momentarily or permanently. Hence, SAM 2 also predicts an occlusion score for each object.
From these outputs, few post-processing steps, including resolving mask covering (based on the predicted IoU), mask refinement and a final 4x upsampling, allow to produce the final segmentation map at the original image size.
Memory bank
The memory bank contains all the information to condition the frame embedding on the past predictions. It is composed of two FIFO queues : one for the N most recent prompted frames and one for the M most recent frames (not necessarily prompted). Depending on the task and the input prompts, there might be one or multiple prompted frames. For instance, in semi-supervised Video Object Segmentation, the video begins with a mask that must be tracked throughout the video. In this case, only the first frame is prompted and the rest of the spatial memory is composed of unconditioned frame features. In addition to those spatial feature memories, the model also stores a list of object pointers, already described in the previous section.
Data
The second main work of the authors is a large-scale database of annotated video. They proceeded in three steps, with interactions between interactive models and human annotators to obtain their final SA-V dataset.
Phase 1. They first used SAM to annotate target objects in 6 FPS (frame per second) videos. For that, pixel-level SAM masks were manually edited with brush and eraser tools. The lack of temporal consistency in SAM’s predictions consequently forced annotators to refine masks often. During this first stage, they collected 16k masklets across 1.4K videos, at an average annotation speed of 37.8 seconds per frame.
Phase 2. During this phase, a SAM 2 model accepting only masks was trained on the annotations from the previous stage and publicly available datasets. Then, the annotators used SAM and brush/erase tools to generate spatial masks in the first frame on each video and propagates them temporally using SAM 2. At any frame of the video, the annotators can modify the predicted mask and re-propagate it with SAM 2, repeating this process until the masklet is correct. During this second stage, they collected 63.5K masklets, at an average annotation speed of 7.4 seconds per frame.
Phase 3. They authors trained another SAM 2 model, this time accepting masks, points and boundings boxes as prompts, and used it as automatic video segmentor. The annotators only needed to provide occasional refinement clicks to edit the predicted masklets, lowering the average annotation time to 4.5 seconds per frame. They collected 197K masklets during this stage.
The final SA-V dataset comprised 50.9K videos captured by crowdworkers from 47 countries. The annotations contains 190.9K manual masklets and 451.7K automatic masklets. A subset of SA-V dataset with only manual annotations and challenging targets is kept for the evaluation.

Figure 3. Examples of predicted masklets of SAM 2.
Evaluation
SAM 2 is compared to other state-of-the-art models on multiple zero-shot video and image tasks.
Promptable video segmentation
They first simulated a realistic user experience for promptable video segmentation. Two settings are considered : an offline evaluation, where multiple passes are made through a video to select frames to interact with based on the largest model error, and an online evaluation, where the frames are annotated in a single forward pass though the video.
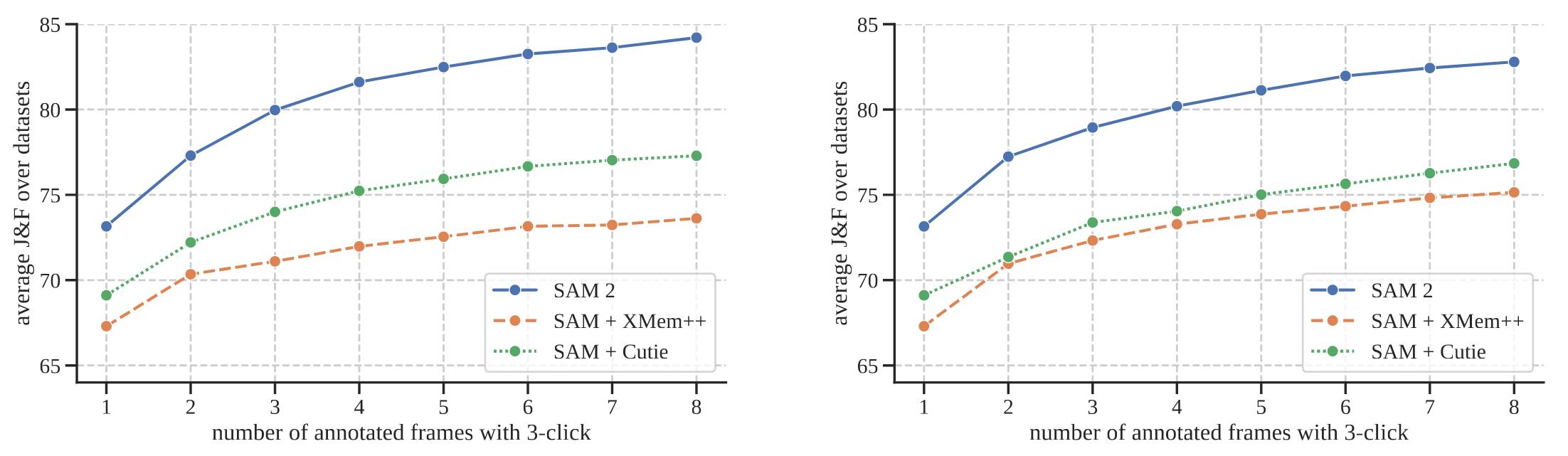
Figure 3. Performance on promtable video segmentation task. Metric is J&F.
Semi-supervised video object segmentation
A second task of interest is semi-supervised video object segmentation task, where only the first frame of the video is provided with a prompt, and the target object must be segmented and tracked throughout the video.

Figure 4. Performance on semi-supervised video object segmentation task. Metric is J&F.
Zero-shot image segmentation
Even though it is made for video segmentation, the authors also evaluate SAM 2 on image segemtation datasets. The evaluation is done on 37 zero-shot datasets, including the 23 datasets used in the SAM paper. The model benefits from the improved image encoder and mask decoder architectures to surpass SAM.

Figure 5. Performance on zero-shot image segmentation task.
Standard VOS task
SAM 2 is also evaluated on a non-interactive, more standard, video object segmentation task, where the prompt is a ground-truth mask on the first frame, an the object must be tracked across the video.
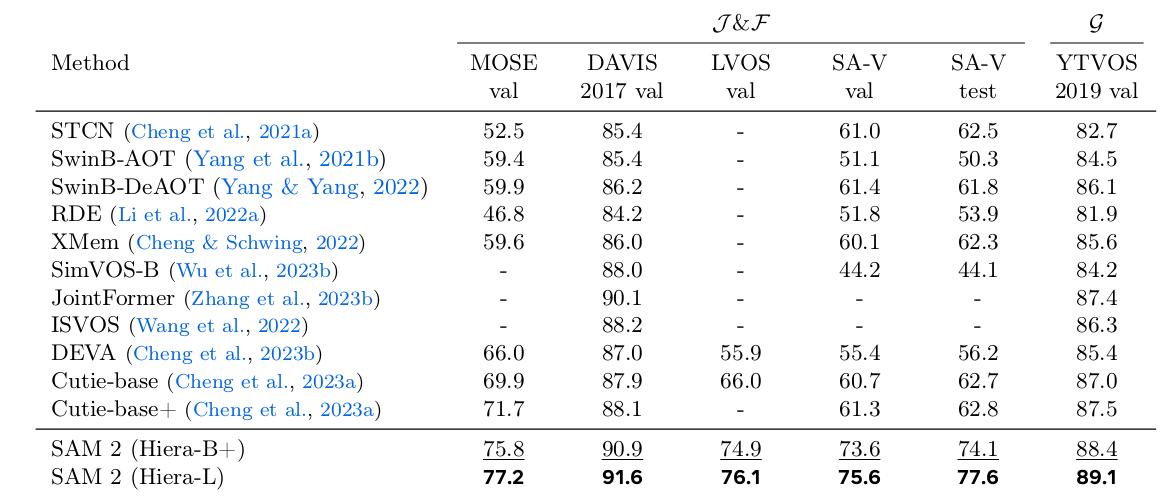
Figure 6. Comparison to prior work on video object segmentation.
Conclusion
SAM 2 is a foundation model for promptable video segmentation. Built upon SAM, it includes several design improvements and additions to achieve state-of-the-art performance on many zero-shot image and video segmentation tasks. The full paper includes more details about the model and experiments, including several ablation studies on the components of the model and the dataset as well as a fairness evaluation.
Reference
-
C. Ryali, Y.-T. Hu, D. Bolya, C. Wei, H. Fan, P.-Y. Huang, V Aggarwal, A. Chowdhury, O. Poursaeed, J. Hoffman, J. Malik, Y. Li, and C. Feichtenhofer. Hiera: A hierarchical vision transformer without the bells-and-whistles. International Conference on Machine Learning (ICML), 2023. ↩