Systematic comparison of semi-supervised and self-supervised learning for medical image classification
Highlights
- Benchmark of SSL methods on medical images.
- Implementation of a real life hyperparameters optimization.
- Comparison of semi-supervised and self-supervised learning.
Note
Code is available here: https://github.com/tufts-ml/SSL-vs-SSL-benchmark
Introduction
In the medical domain there is often a lack of annotated data for deep learning model training while there is a lot of unlabeled data in health records. Semi-supervised and self-supervised learning are methods developed to take advantage of these unlabeled images to improve classification accuracy. The first one trains classifiers jointly with two loss terms, while the second is a two-stage approach, the first to learn deep representation and the second to fine-tune the classifier. However, the two methods are rarely compared. The first question they try to answer is: Which recent semi- or self-supervised methods are likely to be most effective?
But those methods are very sensitive to hyperparameters, and benchmarks often don’t consider realistic hyperparameters tuning (either no hyperparameters tuning or tuning with a huge labeled validation set, bigger than the training set, which is not realistic). In this paper, they try to take that in account by answering the question: Given limited available labeled data and limited compute, is hyperparameter tuning worthwhile?
Methods
Definition of SSL
A unified perspective for different learning paradigms is presented with two available datasets: \(L\) which is a small labeled dataset and \(U\) the unlabeled dataset with \(\lvert U \rvert >> \lvert L \rvert\). The learning process can be written as:
\[v^*, w^* ← argmin_{v,w} \sum_{x,y \in L} \lambda^L l^L(y, g_w(f_v(x))) + \sum_{x \in U} \lambda^U l^U(x, f_v,g_w)\]where \(l^L\) and \(l^U\) are the loss functions linked to the labeled and unlabeled datasets and \(\lambda^L\) and \(\lambda^{U}\) the associated weights. In addition, \(f_v(\cdot)\) denotes a neural network backbone with parameters \(v\) that produces an embedding of the input images and \(g_w(\cdot)\) denotes a final linear softmax classification layer with parameters \(w\).
| Method | \(\lambda^L\) | \(\lambda^U\) |
|---|---|---|
| Supervised | 1 | 0 |
| Semi-supervised | >0 | >0 |
| Self-supervised | pretraining (0) –> finetuning (1) | pretraining (1) –> finetuning (0) |
Compared methods
Supervised learning
Three supervised methods are used as reference to compare with SSL. These supervised methods only use the labeled \((L)\) dataset.
- Sup: to denote a classifier trained with classical multiclass cross entropy loss.
- MixUp: also multiclass cross entropy, but with mixup data augmentation (by linearly combining two training samples and their corresponding labels).
- SupCon: using a supervised contrastive learning loss (pull together samples belonging to the same class in the embedded space while pushing apart from samples of other classes).
Semi-supervised learning
They selected 6 methods of the recent years to cover a wide spectrum of strategies and cost, to take advantage of the unlabeled \((U)\) and labeled \((L)\) datasets jointly.
- Pseudo-label: assigns labels to unlabeled data based on the class with the highest predicted probability.
- Mean teacher: teacher weights are updated as exponential moving average of student weights after each sample, either the sample used is labeled or not.
- MixMatch: uses mixup data augmentation to combine labeled and unlabeled data to compute labels for this new input images.
- FixMatch: combination of pseudo-label method to set a label to unlabeled images if the prediction confidence is high enough with strong data augmentation, which prediction has to match the label set previously.
- FlexMatch: adding a curriculum notion to FixMatch to consider different learning status and learning difficulties of different classes, basically adjusting the threshold of confidence to define a class to an unlabeled image.
- CoMatch: learns jointly class probability and low-dimensional embeddings to impose a smoothness constraint and improve the pseudo-labels, while those last regularize the structure of the embeddings through graph based contrastive learning.
Self-supervised learning
In addition, 7 self-supervised methods are compared:
- SimCLR: contrastive learning self-supervised method based on data augmentation using a learnable nonlinear transformation between the representation and contrastive loss to improve the learned representations.
- MOCO v2: for momentum contrastive, which uses a dynamic dictionary with a queue and a moving-averaged encoder that facilitates contrastive unsupervised learning.
- SwAV: contrastive learning that does not compare features directly but compares different augmentations of the same images.
- BYOL: it is based on two networks (online & target) that learn from each other, the online one learns to predict what will be the representation created by the target one from different augmentations of the same image.
- SimSiam: siamese networks maximizing the similarity between two augmentations of one image, with one making a prediction.
- DINO: named after self-distillation with no labels, several transformations of an image passed through student and teacher networks, similarity of the features extracted is computed as loss, and again the teacher weights are updated with an exponential moving average of the student parameters.
- Barlow Twins: introduction of an objective function to make as close as possible to identity matrix the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of the same image to reduce redundancy in the components of the vectors.
Datasets and training parameters
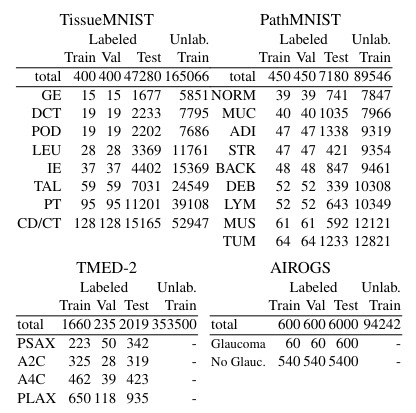
Four datasets with different characteristics are used to compare the 16 methods.
| Dataset | Image type | Number of classes | Resolution |
|---|---|---|---|
| TissueMNIST | Kidney cortex cells | 8 | 28*28 |
| PathMNIST | Colorectal cancer histology | 9 | 28*28 |
| TMED-2 | Echocardiogram US images | 4 | 112*112 |
| AIROGS | Retina color fundus | 2 | 384*384 |
The details of the images’ distribution are in the following table, with the number of images labeled or not by category. The two first datasets are entirely labeled, so a part of the images were considered as unlabeled to fit the training paradigm of SSL.
Here are some images examples.
Experimental setup
For the low resolution images ResNet-18 is used, WideResNet-28-2 is used for TMED-2 and ResNet-18 or 50 are tested for AIROGS dataset.
A maximum of 200 epochs is performed and training is stopped if the balanced accuracy plateaus for 20 consecutive epochs.
Hyperparameters (learning rate, weight decay and unlabeled loss weight, in addition to the parameters specific for each method) optimization is made for each method and dataset. To fit with real life constraints, they fixed a certain number of hours with a NVIDIA A100 GPU for each hyperparameter optimization (25h for PathMNIST, 50h for TissueMNIST and 100h for TMED-2 and AIROGS). Within this fixed budget, a random search of hyperparameters is done, taking the best using the validation set.
Results
Five separate trials were performed and mean balanced accuracy is calculated each 30 or 60 minutes on validation and test sets.
Balanced accuracy on test set over time is represented for each dataset and method. As a roughly monotonic improvement in test performance is observed over time despite using a realistic-size validation set, they conclude that checkpoint selection and hyperparameters optimization can be effective with a realistically-sized validation set.
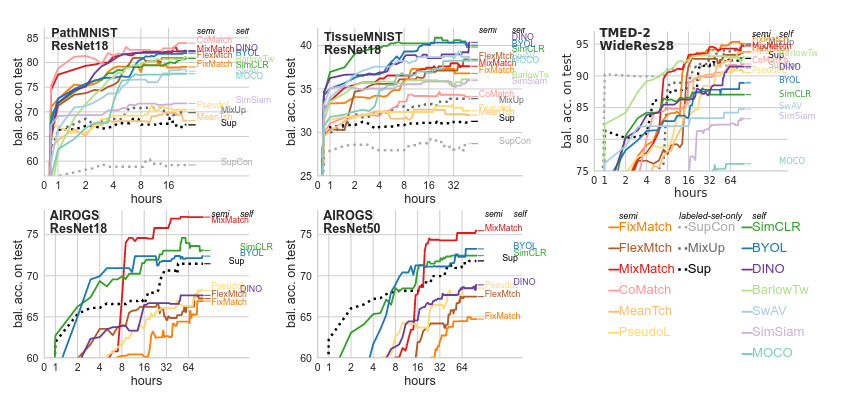
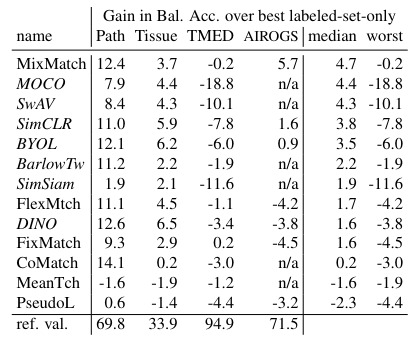
All the methods are compared and none of them clearly stands out from the other depending on the dataset. So they measure the balanced accuracy relative gain over the best supervised method for each dataset. MixMatch represents the best overall choice.
The tuning strategy, even though it reserves data for a validation set, is competitive in comparison with transferring the hyperparameters from another dataset (natural images or medical images) as it may have been done in other benchmark papers.
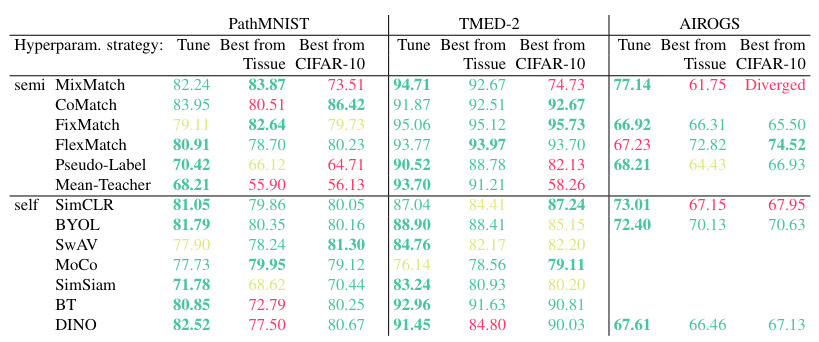
Discussion
SSL provides a tangible performance gain, but it depends on the dataset (a smaller performance improvement is observed for TMED-2). However, they insist on the importance of the selection of the hyperparameters and proper evaluation protocol depending on specific needs. Especially MixMatch requires careful hyperparameter tuning when applied to a new dataset.