Understanding and Mitigating Human-Labelling Errors in Supervised Contrastive Learning
Highlights
- Insight into human-labelling errors vs. synthetic-labelling errors ;
- Quantification of human-labelling errors in supervised contrastive learning framework ;
- Proposition of SCL-RHE, a refined contrastive objective to improve robustness to human-labelling errors with computational efficiency ;
- Improved performance for pre-training and fine-tuning errors on vision datasets for top-1 classification ;
- Demonstrate some robustness to synthetic-labelling errors.
Contrastive learning
Principle
Contrastive learning is a learning strategy within the representation learning framework; it aims to represent data in a lower-dimensional space, known as the latent space. It is also part of metric learning: in this space, the distances between objects are meaningful in relation to a similarity criterion. In contrastive learning, this similarity criterion is learned by bringing some samples closer together while pushing others apart. A sampling policy is chosen, which assigns to each sample (the anchor) a set of samples that should be closer (the positive set) and a set that should be pulled apart (the negative set). Contrastive learning is often used for pretraining, as it structures the latent space.
Unsupervised contrastive learning
Many unsupervised contrastive learning framework are known for pretraining: SimCLR (the reference framework), MoCo (adding momentum), BYOL (only positives)… In this framework, the positive set is formed of samples which are data augmentations of the anchor.
Supervised contrastive learning (SCL)
Contrastive learning can also be applied in a supervised fashion. The article which popularized supervised learning is P. Khosla et al., Supervised Contrastive Learning, NeurIPS 2020. The positive set is the set of samples that have the same label as the anchor.
Contrastive learning drawbacks
- Some contrastive losses can be null if the negative(s) is(are) already further from the anchor than the positive(s). A lot of techniques are developed to adapt the sampling strategy, for example by choosing “hard negatives”, i.e. negatives that are close to the anchor.
- contrastive learning often is computationally heavier as the loss is computed from an anchor but also the associated positive(s) and negative(s). The way of forming the batch, drawing samples etc. can have an impact.
Gap in the literature
The authors identified several gaps in the literature:
- The impact of labeling errors has been studied in classical supervised learning methods, but its effect on contrastive learning is more complex, as it influences the pairing of samples and requires further investigation.
- Additionally, these studies primarily focus on synthetic data with very high error rates, which may be unrealistic. Human errors tend to be less frequent in widely used datasets (around 5%).
- These studies often emphasize “certain” samples, which makes them more prone to overfitting and/or computationally intensive.
- Synthetic and human errors exhibit different characteristics: human errors arise from visual similarity between object classes, while synthetic errors are arbitrary.
Contributions
To answer this gap, the author proposes to:
- Analyse the impact of labelling errors in the case of SCL ;
- Analyse the characteristics of human labelling errors and the specific impact in the case of SCL ;
- Propose a new SCL objective which aims at being computationally efficient with state-of-the-art result because of human-labelling error robustness.
Human-labelling errors and synthetic label errors
Notation
- assigned label = the label given by the annotator vs. latent label = the ‘true’ label of the sample.
- True positive = a sample that is assigned the same class as the anchor and their latent class are also matching vs. false positive = a sample with the same assigned class as the anchor but they are in reality from different classes.
- True negative vs. false negative = same as true positive and false positive but in the case of different assigned labels.
- Easy positive = a true positive that is close to the anchor in the latent space: it means it is easy for the model to see these samples are similar vs. hard positive a positive far from the anchor in the latent space.
- Easy negative = a true negative that is far from the anchor, i.e the model finds it easy to separate these samples vs. hard negative = a sample that is close to the anchor in the latent space.
Human-labelling error reference
This paper mainly relies on the article C.G. Northcutt et al., Pervasive label errors in test sets destabilize machine learning benchmarks, NeurIPS2024 that identifies the label errors in ten of the most commonly-used computer vision, natural language, and audio datasets. The visual datasets include MNIST, CIFAR-10, CIFAR-100, Caltech-256, ImageNet, QuickDraw. An API to run through label errors is available here with the associated Github to load them.
Labelling error impact on SCL
In a supervised classification setting for example, a labelling error will alway have an adverse impact in the loss. However, in supervised contrastive learning, it is more complex as described Figure 1.

By grouping the cases described in the Figure 1, for a given constant error rate \(\tau\) and a number of classes \(C\), a false positive rate \(P_{FP}\) and a false negative rate \(P_{FN}\) can be derived. If \(\tau\) is negligible :
\[P_{FP} \approx 2\tau\]and:
\[P_{FN} \approx \frac{2\tau}{C-1}\]Thus for a high number of classes, the rate of false positive is higher, for example for \(\tau = 0.05\) and 200 classes, \(P_{FP}=9.75\%\) and \(P_{FN}=0.05\%\). An empirical evidence is also proposed on the CIFAR-100 dataset where 99.04% of incorrect signals come from positive pairs.
They choose to focus on positive pairs.
Human-labelling error vs. synthetic label error
They made the following experiment on both CIFAR-10 and ImageNet-1k datasets to qualitatively highlight the difference between human-labelling error and synthetic error:
- Train a ViT-based model on a dataset
- Identify human error on test set using the reference paper previously described
- Generate another test set with 20% synthetic errors on label by randomly picking a wrong class
- Measure similarity between true positives, true negatives and false positives
- Plot distributions
A result is shown Figure 2.
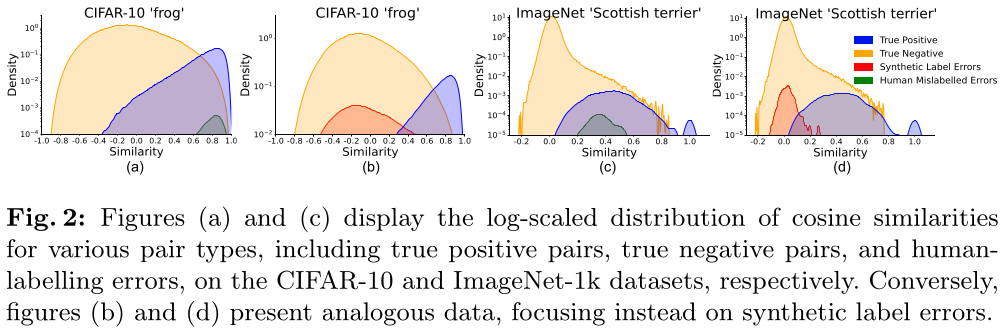
The overlap between true positives and human errors is higher than between true positives and true negatives. The overlap between true positives and human errors is also higher than between true positives and synthetic errors. This is a clue that human errors are made between images that have high visual similarities. It also explain effectiveness of methods to tackle synthetic noise by giving more confidence to pairs closely aligned, and that they may be non effective for human errors.
They interpret it in the case of SCL by saying that false positives will mostly be easy positives.
New SCL objective: SCL-RHE
Their new objective must satisfy two conditions: (P1) ensuring that the latent class of positive samples match the anchor latent class (i.e. drawing true positives) and (P2) deprioritize easy positives.
They derive a new distribution from which the positive will be sampled:
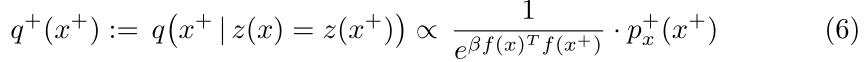
which is formed by a coefficient that gives more weight to samples far from the anchor and a probability distribution which is the true positive distribution (unknown). This distribution is then derived using the perspective of Positive-Unlabeled learning and integrated in the loss. The expectations obtained in the loss are then approximated and samples are drawn using a Monte Carlo importance sampling strategy. Please refer to the article and its supplementary material for more detailed explanation.
Qualitatively, samples will be mostly drawn from the hard positives and sometimes in the negative set.
They also use this method for negative pairing even if the impact is supposed to be less important.
Experiments
Three setups are considered:
- from scratch with human-labelling errors
- transfer learning with pretrained weights (with human-labelling error)
- pre-training with high levels of synthetic errors
They use the official train-test splits, and different architectures (BEiT/ViT-based and ResNet-50).
1. Training from scratch
SCL is used for a pre-training task then a classification head is added to evaluate the classification performances with a frozen network. The datasets considered are CIFAR10, CIFAR100 and ImageNet-1k (error rate 5.85%).
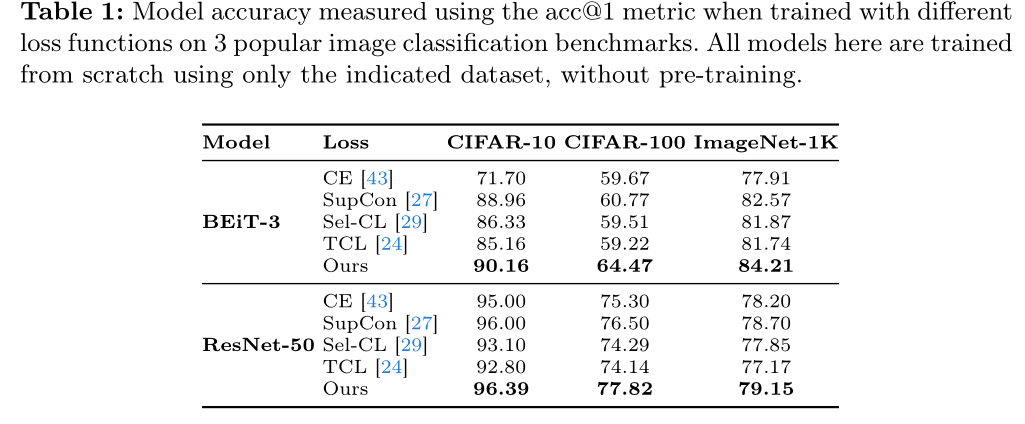
The performances are better than classical supervised and classical Supervised CL (see Table 1). They are also better than Sel-CL and TCL, methods that mitigate synthetic errors, maybe because these methods discard some samples that may deteriorate their performances. Transformers models are less efficient for “small” datasets.
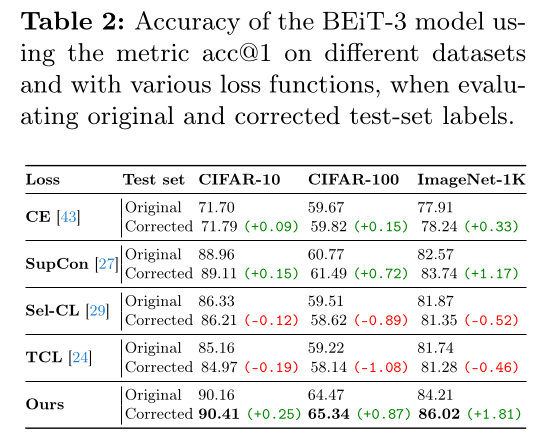
They also evaluated on the corrected test splits: SCL-RHE has the best improvement (see Table 2), which may show that it is less overfitting on human errors. SCL-RHE is successful at less overfitting.
2. Transfer learning
They use the pre-trained weights of ImageNet-21k, and finetuned on smaller datasets CIFAR-100, CUB-200-2011, Caltech-256, Oxford 102 Flowers, Oxford-IIIT Pets, iNaturalist 2017, Places365, and ImageNet-1k. It also gave the best performances.
3. Robustness to synthetic noisy labels
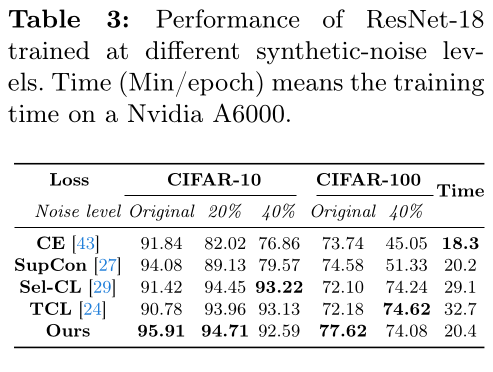
Existing methods to tackle synthetic labels errors have low computational efficiency: extra module for confidence, calculate graphs… They wanted to test their method in this setting. They trained the models on CIFAR dataset with a train dataset corrupted with synthetic errors. They used a ResNet-18. SCL-RHE is faster than other mitigation techniques, and have stable performance across error rates (see Table 3.), with the same order of magnitude than SupCon without synthetic errors.
Conclusion
The limitations are:
- Determining a constant error rate, but a default value can be taken and they found some low sensitivity.
- Not SOTA for synthetic labels, but stays performant.
- They chose a setting of low error rate and high number of classes
They proposed a new objective that helps performance by mitigating human-labelling errors.