Vision Transformers Need Registers
Highlights
- They identify artifacts in feature maps produced by Vision Transformers (ViT)
- Artifacts are high-norm tokens appearing in low-informative parts of the image
- They solve the problem by providing additional tokens (registers) to the input sequence
- Feature maps are smoother, and it improves performance in dense prediction and object discovery tasks

Introduction
The DINO algorithm produce models that have interpretable attention maps: the last attention layer naturally focuses on semantically consistent parts of the image (Fig 2). This allows object discovery algorithm such as LOST. However these methods doesn’t work anymore with DINOv2 and other ViT (DeiT-III and OpenCLIP) due to the presence of artifacts in the feature maps.
In this paper they try to better understand this phenomenom and find a solution to this problem.

Understanding the problem
Artifacts are high-norm tokens

The distribution of the norm of the tokens is clearly bimodal. Tokens that have a norm higher than 150 will be considered as “high-norm” or “outlier” tokens
Outliers appear during the training of large models.
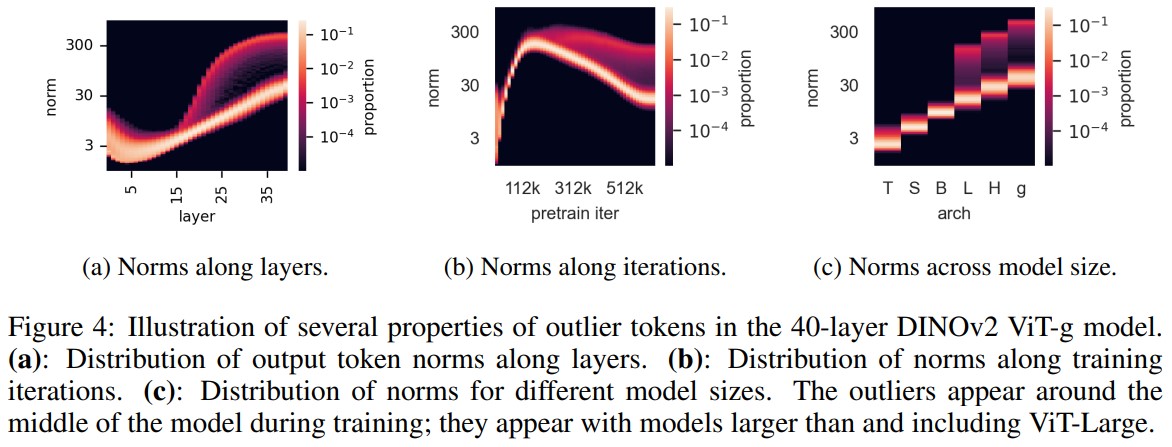
High-norm tokens appear at layer 15/40, at one third of the training and only for large size ViT (ViT-H, ViT-L and ViT-g)
High-norm tokens appear where patch information is redundant

See Fig 5a. and Fig 2.
High-norm tokens hold little local information
They train two linear models: one to predict the position of the patch in the image, one to predict the pixel values of the images. For both tasks the outliers have lower performance than normal tokens (Fig 5b.)
Artifacts hold global information
They train a logistic regression classifier directly from the patch embeddings and measure its accuracy to predict the image class. High-norm tokens have a much higher accuracy than normal tokens.

Table 1. Image classification via linear probing on normal and outlier patch tokens.
Hypothesis and remediation
They make the following hypothesis: large, sufficiently trained models learn to recognize redundant tokens, and to use them as places to store, process and retrieve global information.
They propose a simple fix: they explicitly add new tokens to the sequence, that the model can learn to use as registers. They add these tokens after the patch embedding layer, with a learnable value, similarly to the [CLS] token.
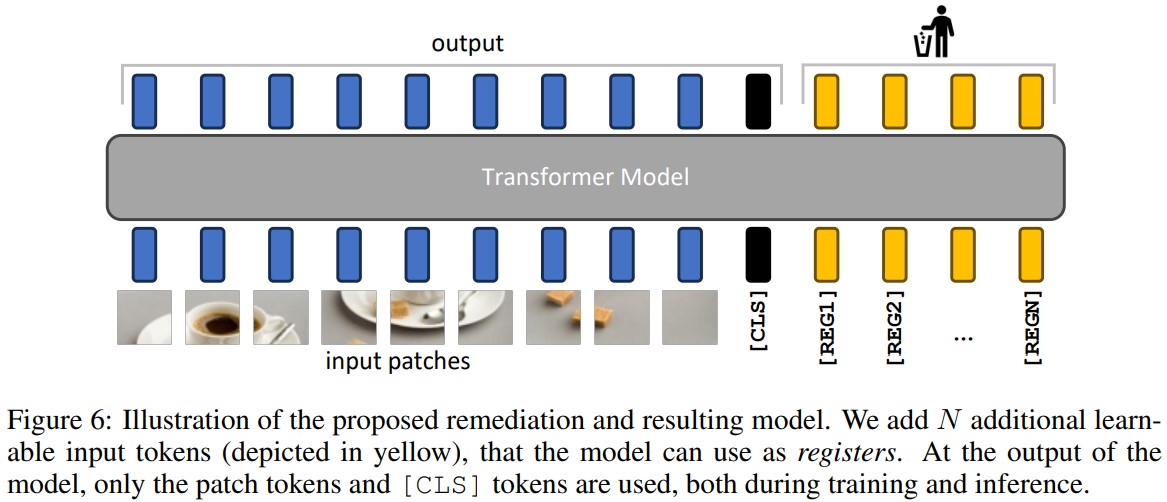
Experiments
They train three different state-of-the art ViT models:
- DeiT-III: supervised training recipe on ImageNet-22k.
- OpenCLIP: image-text supervision, on a corpus based on Shutterstock licensed images.
- DINOv2: unsupervised learning on ImageNet-22k.

Figure 7. Effect of register tokens on the distribution of output norms.
Using register tokens effectively removes the norm outliers that were present previously.
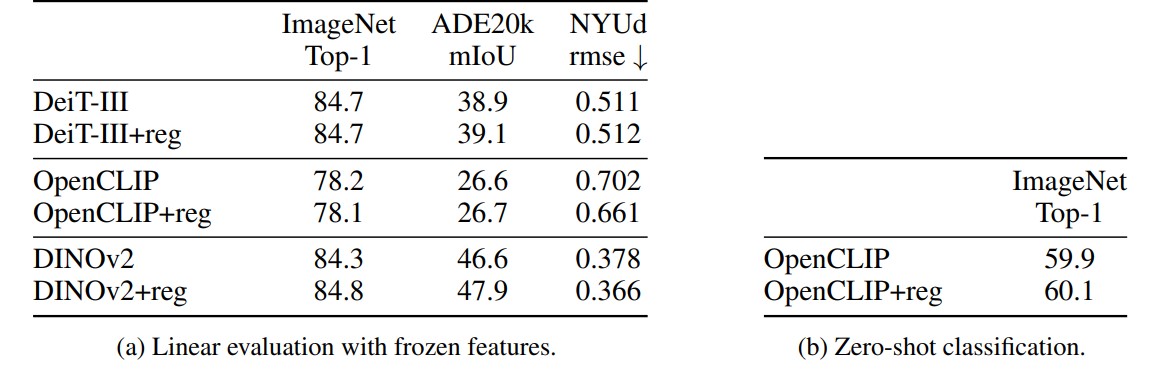
Table 2. Evaluation of downstream performance of the models.
To check that the use of registers doesn’t affect the quality of the representation, they evaluate the models on three tasks with linear probing: ImageNet classification, ADE20k segmentation, NYUd monocular depth estimation.

Using one register is enough to get rid of the artifacts. On dense tasks there is an optimum number of registers but one ImageNet keep increasing with more registers. They decide to use 4 registers in all experiments.
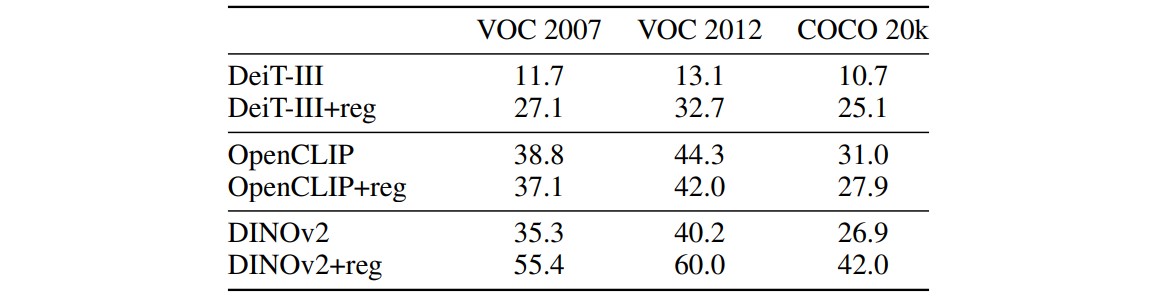
Table 3. Unsupervised Object Discovery using LOST.
They use LOST for Unsupervised Object Discovery and observe significant improvements.

Qualitative results
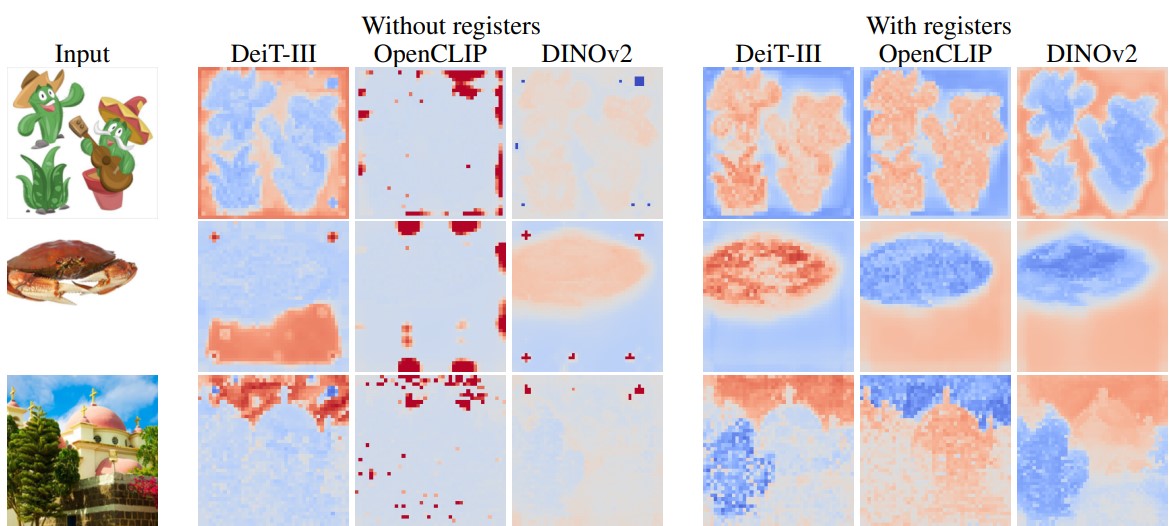
Figure 20. First principal component of the feature maps output.
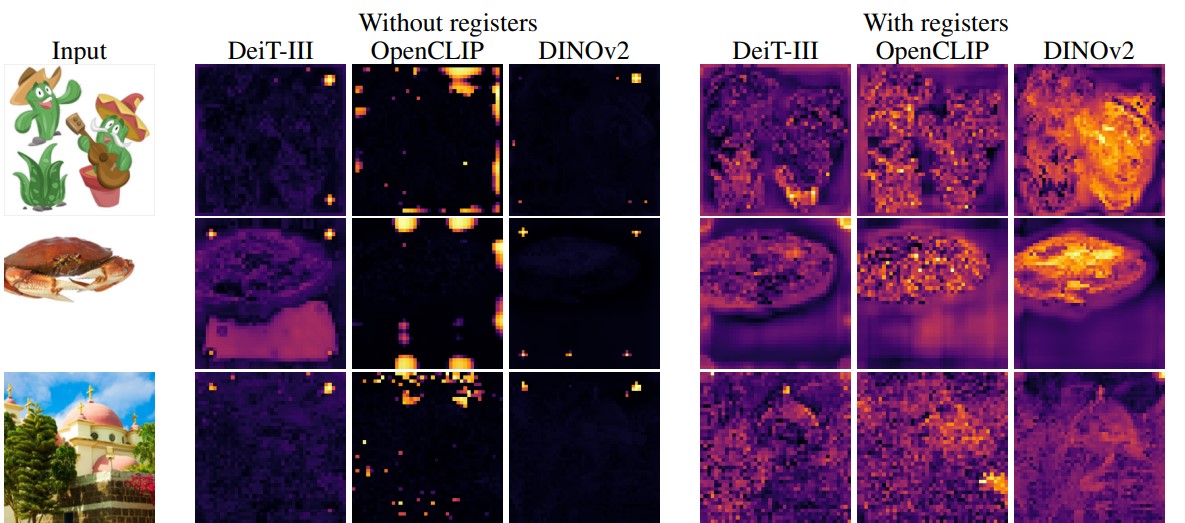
Figure 21. Maps of token norms.