HeartBeat: Towards Controllable Echocardiography Video Synthesis with Multimodal Conditions-Guided Diffusion Models
Notes
- No code available :(
Highlights
- Develop a diffusion-based framework for controllable and high fidelity echocardiography video synthesis
- Integrate 7 different conditions simultaneously to guide controllable generation
- Decouple the visual concepts and temporal dynamics learning using a two-stage training scheme to simplify model training
- Assess generalization capacity by training mask-guided cardiac MRI in few-shots
- Evaluation from two public datasets: CAMUS (echocardiography) and M&Ms (cardiac MRI)
Motivations
- Generate controlled synthetic ultrasound videos to accelerate novice training and intelligent systems development
- Solve data scarcity issue
Methodology
Overall architecture
-
Involves a two-stage training scheme
-
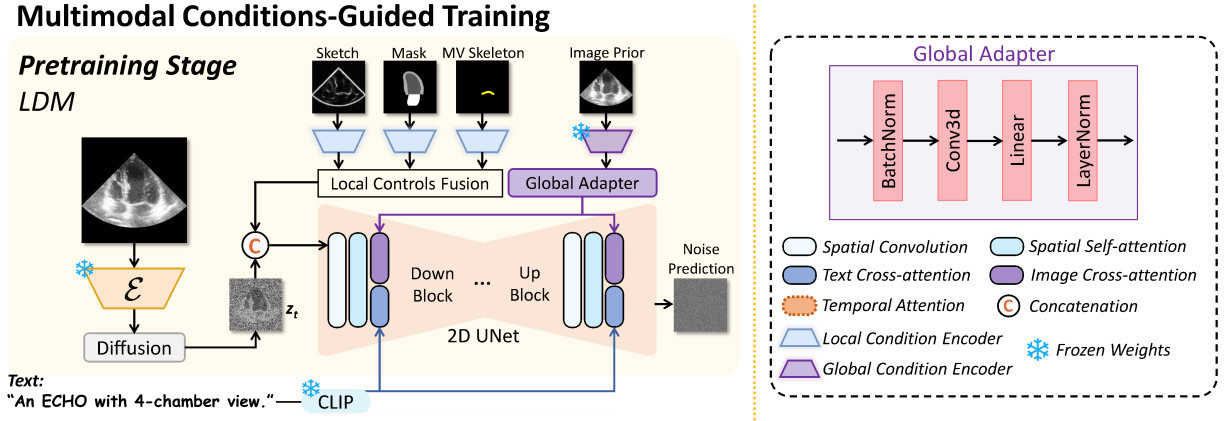
Pretraining stage
➔ Train an LDM (Latent Diffusion Model) to learn visual concepts from 2D images
➔ A standard 2D UNet is used as the denoising network for controllable image generation ➔ UNet is composed of stacked blocks, where each contains a spatial convolution layer, a spatial self-attention layer, and a cross-attention layer that controls the synthesis by text and image
➔ Two types of conditioning: local conditions for fine-grained control (sketch, mask, mitral valve skeleton) and global conditions for coarse-grained control (image prior encoded from a pretrained MedSAM image encoder and text from the pretrained CLIP text encoder)
➔ Two conditioning schemes:- Local condition: each local condition is first encoded in parallel. The obtained local conditional features are then fused by element-wise addition. Last, such features are concatenated with the noisy image \(z_t\) along the channel dimension to form local control signals.
- Global condition: there are two global conditions, one to capture image texture and one for text. These global conditions are integrated through cross-attention mechanisms using the following scheme:
\(CrossAttention(Q^T, K^T, V^T) + CrossAttention(Q^I, K^I, V^I)\)
where: \(Q^T, Q^I \in \mathbb{R}^{B \times H \times W \times C}\), \(K^T, K^I, V^T, V^I \in \mathbb{R}^{B \times N \times C}\), with \(B\) the batch size, \(H\) the height, \(W\) the width, \(N\) the numbers of tokens from text (\(T\)) and image (\(I\)) prior conditions, and \(C\) the hidden dimension
➔ Learn a global adapter to align the global image prior embeddings and the text embeddings
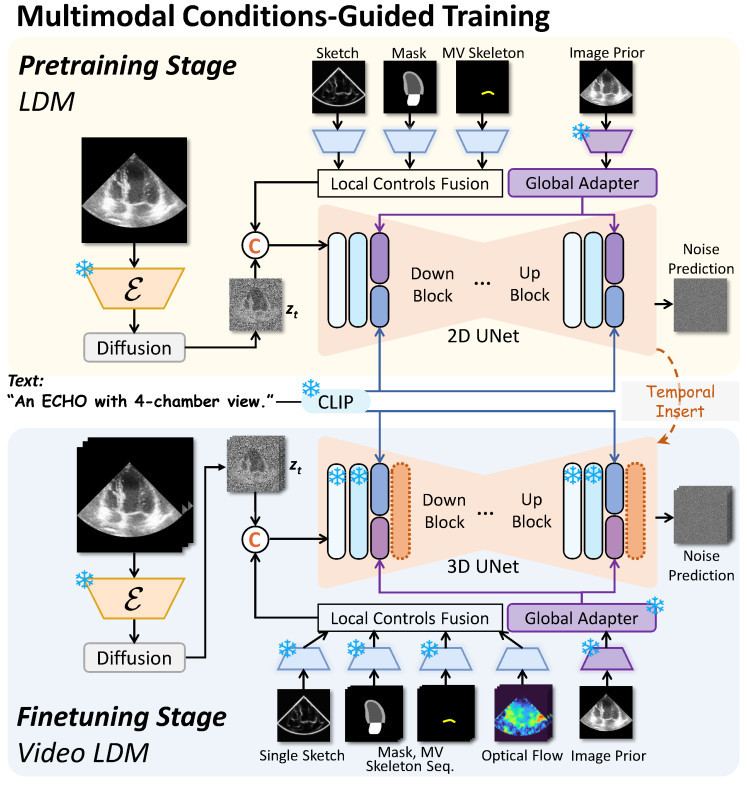
- Finetuning stage
➔ Train a video LDM (VLDM) to generate controllable video
➔ Extend the 2D UNet to the 3D counterpart using a simple inflation strategy
➔ Inflate all the spatial convolution layers at the temporal dimension with t=1
➔ Insert a temporal self-attention layer following the cross-attention layer in each block 1
➔ Two types of conditioning: local conditions for fine-grained control (sketch, time-series masks, time-series mitral valve skeleton, time-series optical flow) and global conditions for coarse-grained control (image prior encoded from a pretrained MedSAM image encoder and text from the pretrained CLIP text encoder)
➔ Two conditioning scheme: summation + concatenation from the input noisy image for the local conditions and cross-attention for global conditions (just like in the pretraining stage)
➔ Global condition injection method: in this case \(Q^T, Q^I \in \mathbb{R}^{B F \times H \times W \times C}\), \(K^T, K^I, V^T, V^I \in \mathbb{R}^{B F \times N \times C}\), with \(F\) the length of frames
Experiments
- Validation on the CAMUS dataset: 884 echocardiographic videos: 431 apical two-chamber (A2C) and 453 apical four-chamber (A4C)
- The dataset was split randomly into 793 and 91 videos with 16 frames for training and testing at the patient level
- Text prompts (i.e., “An ECHO with 2/4-chamber view.”) were set for all videos according to the actual view
- For few-shot generalization validation, the authors employed 50 CMR volumes from M&Ms Challenge as the training set
- All frames / slices were resized to \(256 \times 256\)
- LDM was developed upon Stable Diffusion and initialized using the public pretrained weights
- During finetuning, the spatial weights were frozen except for the newly added optical flow encoder and the temporal layers which were also kept trainable
- Batch sizes of 64 and 16 for the first and second stages of training
During the whole training, all conditions were jointly used. This way, the model did not have to be finetuned for each unique combination of multimodal conditions every time, enabling the flexibility to drop several conditions during inference
- The CMR synthesizer was merely conditioned on mask volumes, and initialized with US-trained HeartBeat.
- The learning rate was initialized to 1e-4 after 500 steps of warm-up strategy and decayed by a cosine annealing scheduler
- All models were trained using the Adam optimizer for 200 epochs
- The models of the last epoch were selected.
- 4 NVIDIA A6000 GPUs were used during training
Results
Qualitative results
- Several controlled guided sequences were generated to visually assess to impact of the different conditions:
➔ Image prior-controlled echocardiography video synthesis
➔ Sketch-controlled echocardiography video synthesis
➔ Mitral valve motion-controlled echocardiography video synthesis
➔ Various conditions-controlled echocardiography video synthesis
➔ Generalization to 3D CMR synthesis
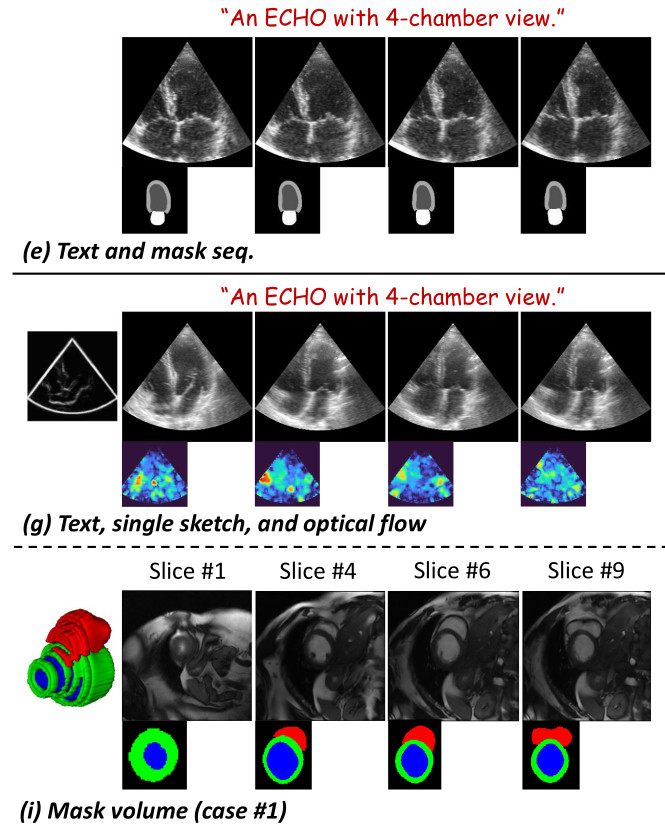
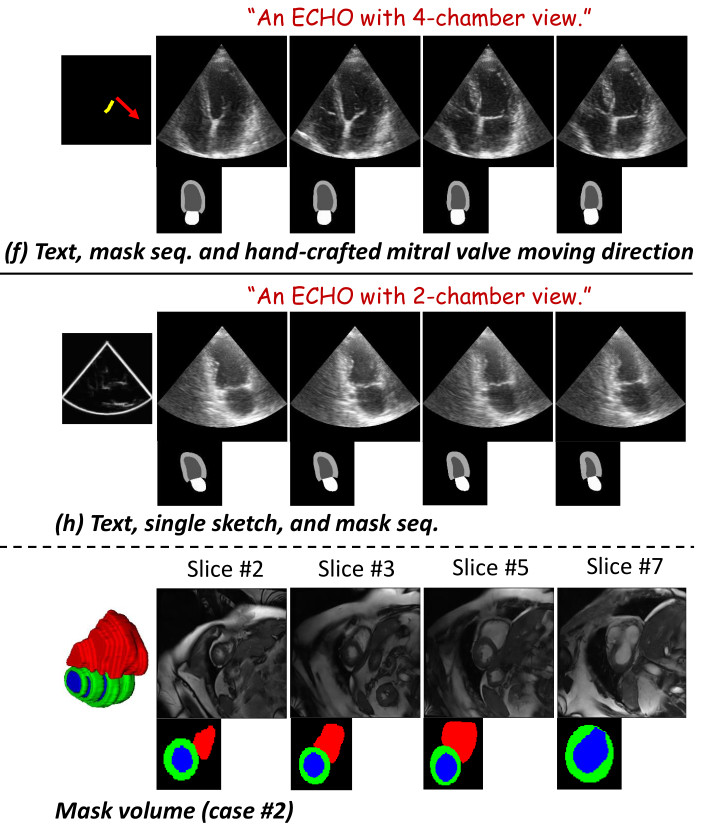
Quantitative results
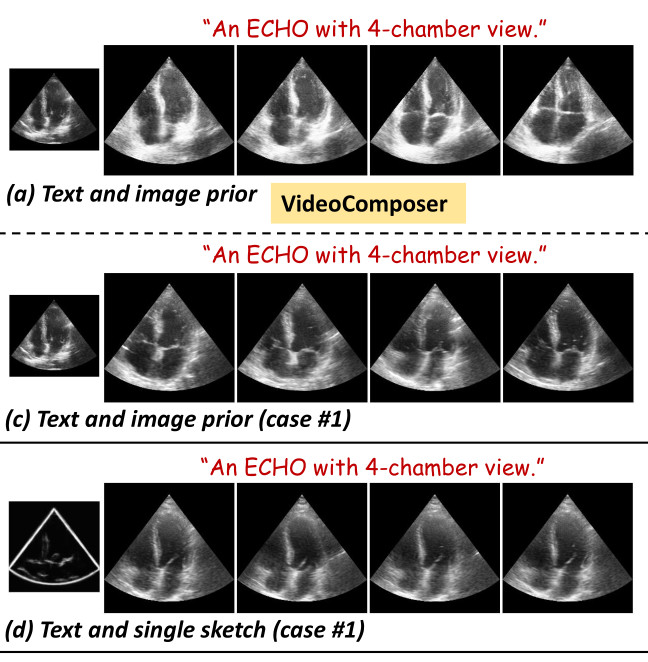
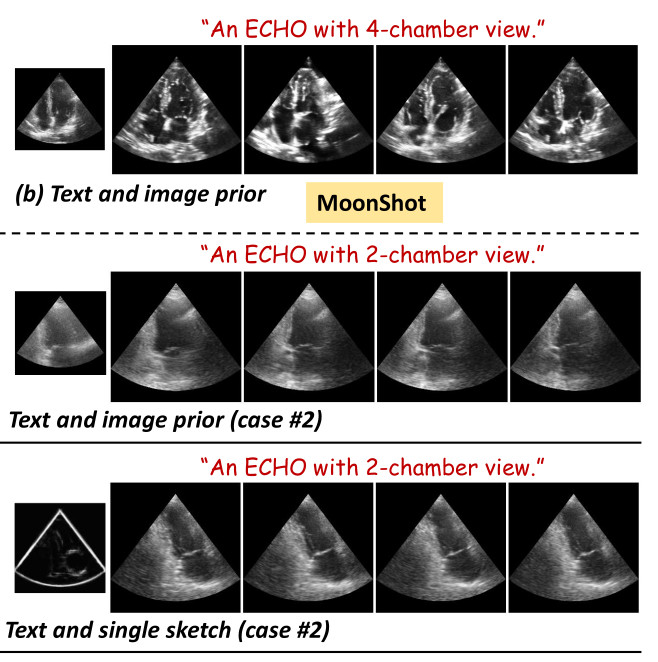
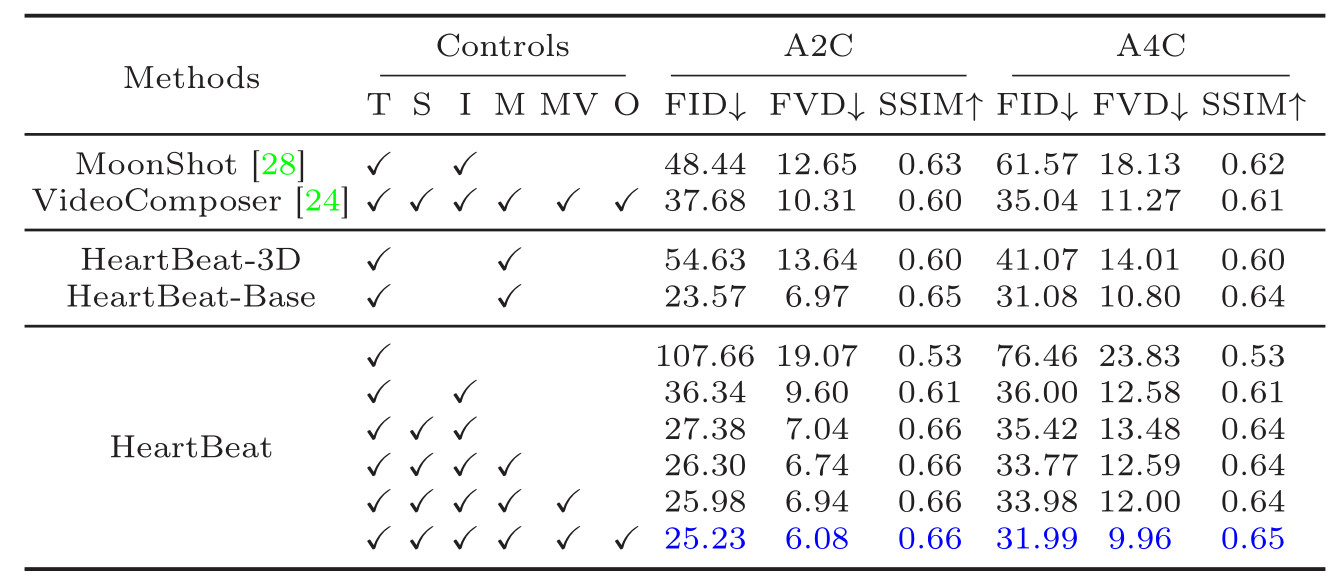
- Comparison with two other existing methods: VideoComposer and MoonShot
- Three metrics were used to evaluate the performance
➔ Fréchet Inception Distance (FID) for image quality evaluation at the feature level
➔ Fréchet Video Distance (FVD) for visual quality and temporal consistency assessment at the video level
➔ Structure Similarity Index (SSIM) score to assess the controllability
Conclusions
- This paper presents a novel diffusion-based HeartBeat framework for controllable and flexible echocardiography video synthesis
- Multimodal control information were integrated, including local and global conditions to separately provide fine- and coarse-grained guidance
- Generalization was investigated from echocardiography 2D+t to 3D cardiac MRI image synthesis
- The interest of the integrated text condition (“An ECHO with 4/2-chamber view”) appears to be limited but opens the door for more sophistigated conditionings
References
-
Video diffusion models, J. Ho et al., 2022 ↩