ECML PKDD 2025 - Selection of papers
Note
The purpose of this post is to compile a number of papers that have been presented at the 2025 European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD) and which we feel may be of interest for people working in deep learning and/or medical imaging.
You can check the preprint versions of the articles of the main conference here.
Summary
- Note
- Summary
- Talk Is Cheap, Energy Is Not: Towards a Green, Context-Aware Metrics Framework for Automatic Speech Recognition
- Drop-in efficient self-attention approximation method
- How CNNs and ViTs perceive similarities between categories
- Jensen–Tsallis divergence for supervised classification under data imbalance
- TreeDiffusion: Hierarchical Generative Clustering for Conditional Diffusion
- A Complementarity-Enhanced Mixture of Human-AI Teams for Decision-Making
- Towards Better Generalization and Interpretability in Unsupervised Concept-Based Models
- Stable Vision Concept Transformers for Medical Diagnosis
- Improving Novel Anomaly Detection with Domain-Invariant Latent Representations
- AMST: Alternating Multimodal Skip Training
- Revisiting Cross-Modal Knowledge Distillation: A Disentanglement Approach for RGBD Semantic Segmentation
- Cynthia Rudin’s keynotes
Talk Is Cheap, Energy Is Not: Towards a Green, Context-Aware Metrics Framework for Automatic Speech Recognition
M. Ulan, E. Johannes Husom, J. Van den Abeele, Talk Is Cheap, Energy Is Not: Towards a Green, Context-Aware Metrics Framework for Automatic Speech Recognition, In Joint European Conference on Machine Learning and Knowledge Discovery in Databases (2025).
“This paper introduces a novel benchmarking framework that assesses ASR models during inference from both performance and sustainability perspectives. We introduce a multi-metric evaluation approach quantifying Word Error Rate (WER), Real-Time Factor (RTF), Energy Per Audio Second (EPAS), inference latency,GPU Memory Efficiency (GME), and Hardware Utilisation Rate (HUR).”
Drop-in efficient self-attention approximation method
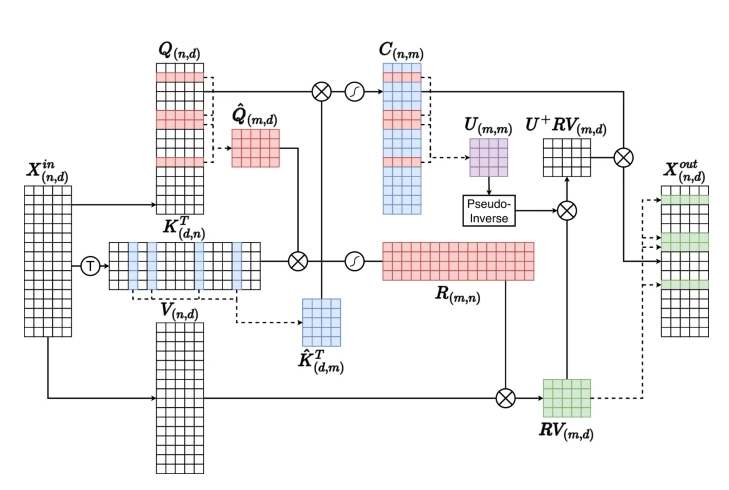
M.-I. Georgescu, E. Fonseca, R. Tudor Ionescu, M. Lucic, C. Schmid, A. Arnab, Drop-in efficient self-attention approximation method, In Joint European Conference on Machine Learning and Knowledge Discovery in Databases (2025).
“In this paper, we propose a novel linear approximation method for Self-Attention inspired by the CUR approximation method. This method, proposed in two versions (one leveraging FlashAttention), is conceived as a drop-in replacement for standard Self-Attention with weights compatibility..”
How CNNs and ViTs perceive similarities between categories
K. Filus, J. Domańska, How CNNs and ViTs perceive similarities between categories, In Joint European Conference on Machine Learning and Knowledge Discovery in Databases (2025).
“The framework introduced in the paper can help to better understand deep models (e.g. what they perceive similar, whether their perception aligns with semantics or with the one of other networks) and their training datasets (e.g. labeling issues, overlapping, duplicated classes). Our methods do not require any images for testing, while our insights and results can serve as a reference for future comparisons and benchmarking due to analyzing a large set of networks. As a large part of the visual and semantic similarities naturally intersect, vision networks should be able to discover such links, and they do”
Jensen–Tsallis divergence for supervised classification under data imbalance
A. Squicciarini, T. Trigano, D. Luengo, Jensen–Tsallis divergence for supervised classification under data imbalance, In Joint European Conference on Machine Learning and Knowledge Discovery in Databases (2025).
“In supervised classification problems using Deep Neural Networks, the loss function is typically based on the Kullback–Leibler divergence. However, alternative entropic divergence formulations, such as the Jensen–Shannon Divergence (JSD), have recently garnered attention for their unique properties. In this study, we delve deeper into the interpretation of the JSD and its generalized form, the Jensen–Tsallis Divergence (JTD), as alternative loss functions for supervised classification. When provided with one-hot encoded distributions for the true label probabilities, we demonstrate that these novel divergences impose an intrinsic output confidence regularization that prevents overfitting.”
TreeDiffusion: Hierarchical Generative Clustering for Conditional Diffusion
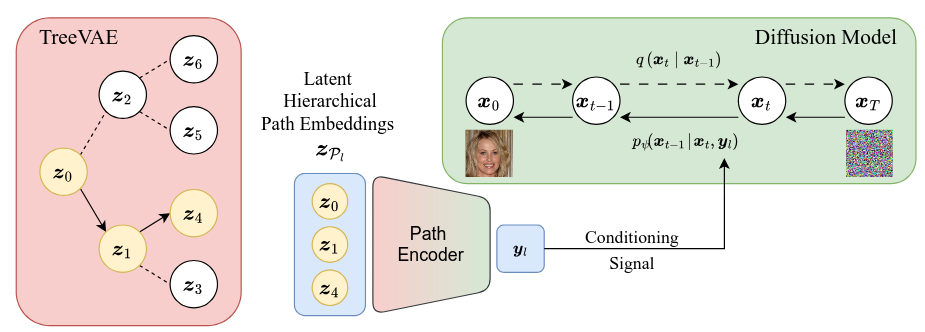
J. da Silva Gonçalves, L. Manduchi, M. Vandenhirtz, J. E. Vogt, TreeDiffusion: Hierarchical Generative Clustering for Conditional Diffusion, In Joint European Conference on Machine Learning and Knowledge Discovery in Databases (2025).
“This paper addresses this problem by introducing TreeDiffusion, a deep generative model that conditions diffusion models on learned latent hierarchical cluster representations from a VAE to obtain high-quality, cluster-specific generations. Our approach consists of two steps: first, a VAE-based clustering model learns a hierarchical latent representation of the data. Second, a cluster-aware diffusion model generates realistic images conditioned on the learned hierarchical structure.”
A Complementarity-Enhanced Mixture of Human-AI Teams for Decision-Making
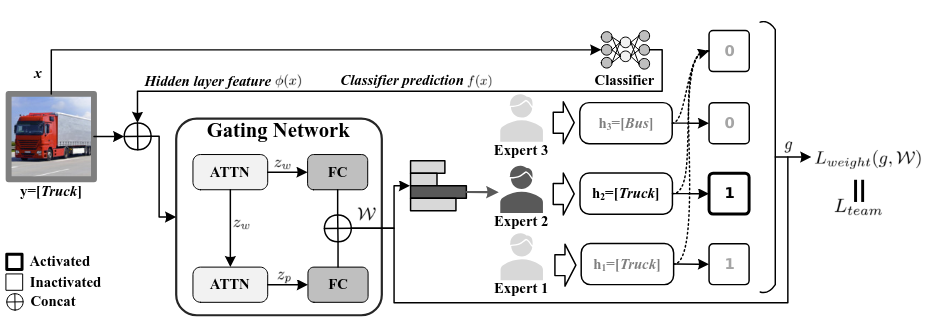
H. Liang, J. Liu, B. Guo, Z. Yu, A Complementarity-Enhanced Mixture of Human-AI Teams for Decision-Making, In Joint European Conference on Machine Learning and Knowledge Discovery in Databases (2025).
“we propose the Complementarity-Enhanced Mixture of Human-AI Teams (CE-MoHAIT) framework. Our approach decomposes the gating network’s output into two branches, i.e., a human expert branch and a classifier branch, thereby explicitly modeling the complementarity between human and AI capabilities.
Towards Better Generalization and Interpretability in Unsupervised Concept-Based Models
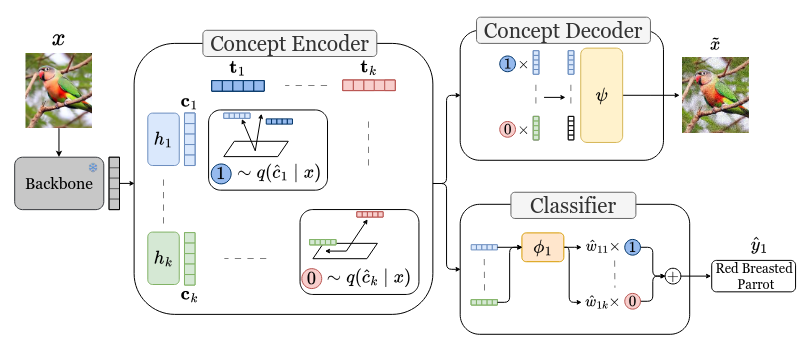
L. Hu, S. Lai, Y. Hua, S. Yang, J. Zhang, D. Wang, Towards Better Generalization and Interpretability in Unsupervised Concept-Based Models, In Joint European Conference on Machine Learning and Knowledge Discovery in Databases (2025).
“To increase the trustworthiness of deep neural networks, it is critical to improve the understanding of how they make decisions. This paper introduces a novel unsupervised concept-based model for image classification, named Learnable Concept-Based Model (LCBM) which models concepts as random variables within a Bernoulli latent space. Unlike traditional methods that either require extensive human supervision or suffer from limited scalability, our approach employs a reduced number of concepts without sacrificing performance.”
Stable Vision Concept Transformers for Medical Diagnosis

L. Hu, S. Lai, Y. Hua, S. Yang, J. Zhang, D. Wang, Stable Vision Concept Transformers for Medical Diagnosis, In Joint European Conference on Machine Learning and Knowledge Discovery in Databases (2025).
“Transparency is a paramount concern in the medical field, prompting researchers to delve into the realm of explainable AI (XAI). Among these XAI methods, Concept Bottleneck Models (CBMs) aim to restrict the model’s latent space to human-understandable high-level concepts by generating a conceptual layer for extracting conceptual features, which has drawn much attention recently. However, existing methods rely solely on concept features to determine the model’s predictions, which overlook the intrinsic feature embeddings within medical images. To address this utility gap between the original models and concept-based models, we propose Vision Concept Transformer (VCT).”
Improving Novel Anomaly Detection with Domain-Invariant Latent Representations
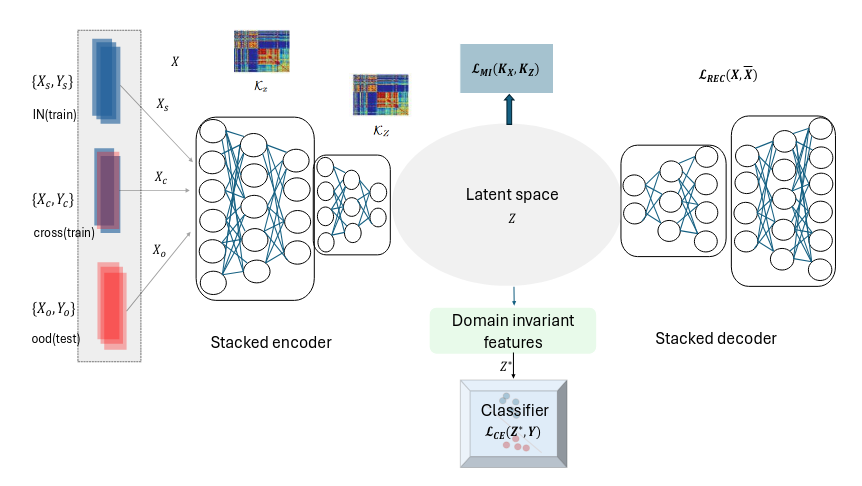
P. Roy, M. Jin, H. Singhal, T. Cody, K. Choi, Improving Novel Anomaly Detection with Domain-Invariant Latent Representations, In Joint European Conference on Machine Learning and Knowledge Discovery in Databases (2025).
“Zero-day anomaly detection is critical in industrial applications where novel, unforeseen threats can compromise system integrity and safety. Traditional detection systems often fail to identify these unseen anomalies due to their reliance on in-distribution data. Domain generalization addresses this gap by leveraging knowledge from multiple known domains to detect out-of-distribution events. In this work, we introduce a multi-task representation learning technique that fuses information across related domains into a unified latent space”
AMST: Alternating Multimodal Skip Training
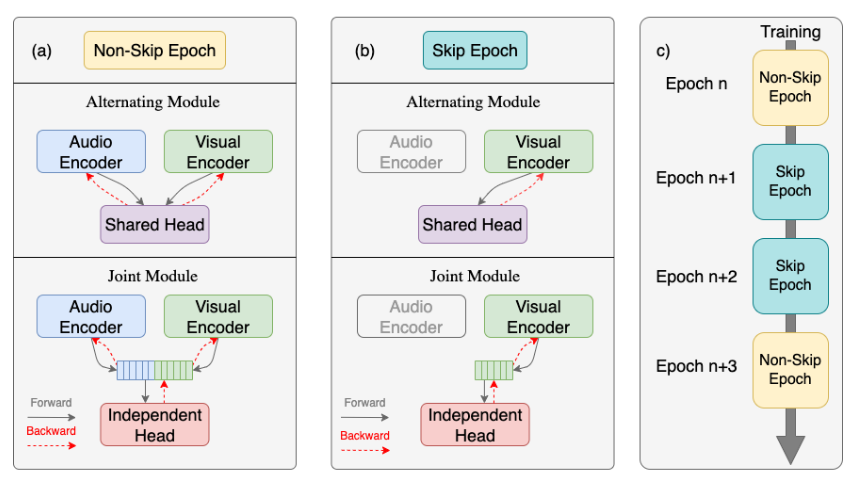
H. Silva, H. Chen, S. Selpi, AMST: Alternating Multimodal Skip Training, In Joint European Conference on Machine Learning and Knowledge Discovery in Databases (2025).
“Multimodal Learning is one of the many fields in Machine Learning where models leverage the combination of various modalities to enhance learning outcomes. However, modalities may differ in data representation and complexity, which can lead to learning imbalances during the training process. […] Given differences in convergence rates, different modalities may harmfully interfere with each other’s learning process when simultaneously trained, as is commonly done in a multimodal scenario. To mitigate this negative impact, we propose Alternating Multimodal Skip Training (AMST) where the training frequency is adjusted for each specific modality.”
Revisiting Cross-Modal Knowledge Distillation: A Disentanglement Approach for RGBD Semantic Segmentation
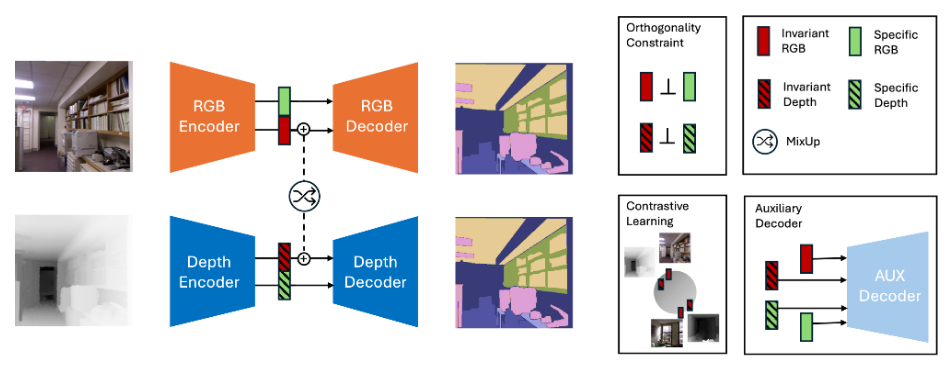
R. Ferrod, C. Fraga Dantas, L. Di Caro, D. Ienco, Revisiting Cross-Modal Knowledge Distillation: A Disentanglement Approach for RGBD Semantic Segmentation, In Joint European Conference on Machine Learning and Knowledge Discovery in Databases (2025).
“we introduce CroDiNo-KD (Cross-Modal Disentanglement: a New Outlook on Knowledge Distillation), a novel cross-modal knowledge distillation framework for RGBD semantic segmentation. Our approach simultaneously learns single-modality RGB and Depth models by exploiting disentanglement representation, contrastive learning and decoupled data augmentation with the aim to structure the internal manifolds of neural network models through interaction and collaboration.”
Cynthia Rudin’s keynotes
Cynthia Rudin presented two keynotes at ECML PKDD 2025, one at the workshop AIMLAI - Advances in Interpretable Machine Learning and Artificial Intelligence, and one during the main conference.
In the first one, entitled Two Indispensable Tools for Scientific Discovery she presneted the applications of two works in which she was involded, PaCMAP and ProtoPNet. The slides of her keynote are available here.
During her second speech, Many Good Models Leads to…, she introduced the concepts of Rashomont Effect and Rashomon Set, and their applications in interpretable machine learning. The slides are available here.
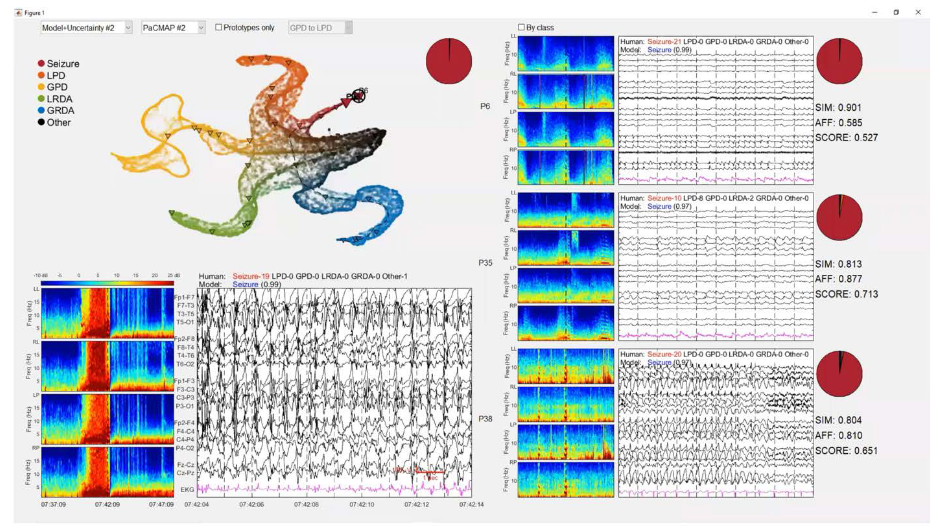
Visualization the last layer of a prototypical network using PaCMAP for EEG monitoring.