Towards Brain MRI Foundation Models for the Clinic: Findings from the FOMO25 Challenge
Introduction
This paper presents the findings of the FOMO25 (MICCAI) challenge, a benchmark designed to evaluate whether self-supervised foundation models for brain MRI can generalize to realistic clinical settings.
Current supervised learning approaches in neuroimaging are limited by the scarcity of high-quality labels and by poor robustness to domain shifts across scanners, sites, and patient populations.
The challenge focuses on self-supervised learning (SSL), where large amounts of unlabeled MRI data are used to pretrain a generic representation model before task-specific finetuning. SSL is a potential solution to the mismatch between abundant clinical imaging data and limited annotations.
Main contributions:
- Release of the FOMO60K dataset [1], a large heterogeneous collection of over 60k structural brain MRI scans.
- A clinically realistic benchmark emphasizing few-shot finetuning, out-of-domain generalization, noisy and heterogeneous clinical data.
- Comparison of SSL objectives, architectures, and scaling strategies across three downstream tasks.
Related Work
The paper situates itself among recent SSL benchmarking efforts in medical imaging.
The SSL3D challenge focused on standardized evaluation with fixed architectures, allowing controlled comparison of SSL objectives but limiting architectural freedom. In contrast, FOMO25 allows arbitrary backbones, finetuning strategies, and preprocessing pipelines.
The CVPR 2025 challenge focused on interactive biomedical segmentation. FOMO25 studies foundation models as general representation learners transferable across different task families.
Challenge Design
Two main tracks

Tack 1 isolates methodological innovation: SSL objectives, architecture design, finetuning strategies. Track 2 measures the practical upper bound achievable using unrestricted data.
FOMO60K Pretraining Dataset
The Method Track restricts participants to the FOMO60K dataset for pretraining. FOMO60K contains:
- 60,529 MRI scans,
- 13,900 sessions,
- 11,187 subjects,
From 16 public datasets: OASIS, BraTS, MSD, IXI, MGH Wild, NKI, SOOP, NIMH, DLBS, IDEAS, ARC, MBSR, UCLA, QTAB, AOMIC ID1000.
It includes a wide range of sequences: T1, MPRAGE, T2, T2*, FLAIR, SWI, T1c, PD, DWI, ADC, and more.
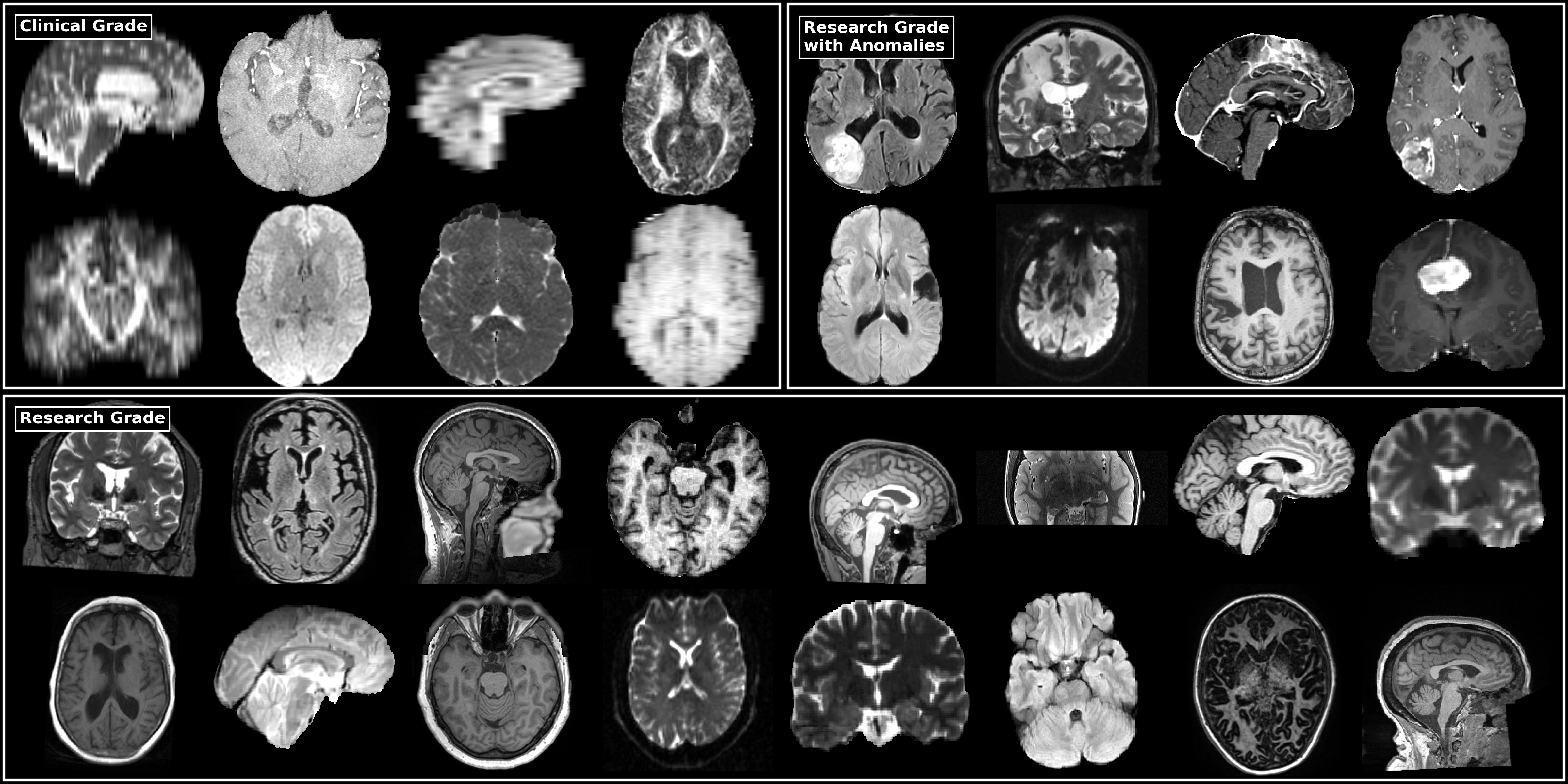
The dataset is intentionally heterogeneous: different scanner vendors, protocols, field strengths, both research and clinical scans. Heterogeneity is central to the challenge objective, since the goal is to learn representations robust to clinical variability.
Minimal preprocessing. All scans are:
- Reoriented to RAS,
- Co-registered within sessions,
- Skull-stripped or defaced.
Evaluation

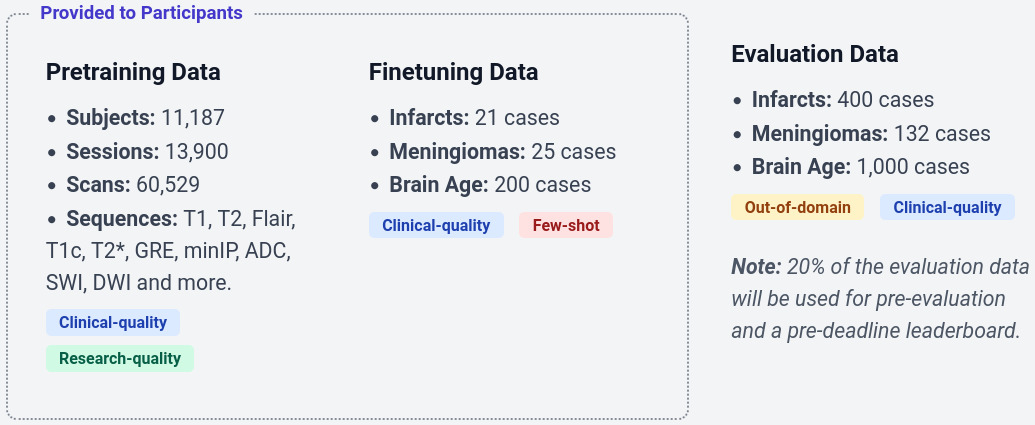
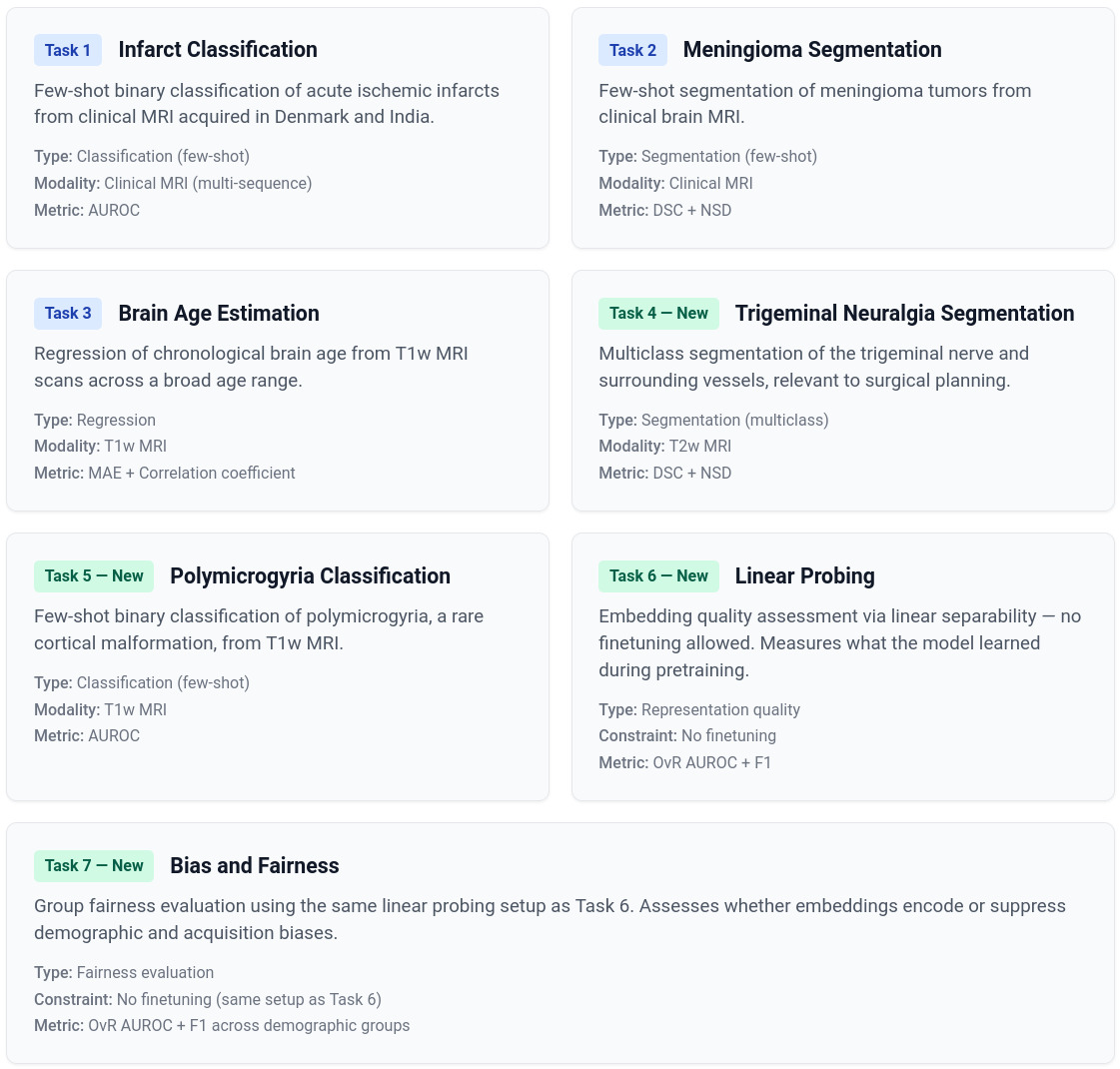
The finetuning datasets are intentionally small to emphasize few-shot learning. The classification and segmentation datasets are from multiple hospitals in India, while the regression dataset drawn from a subset of the dataset in [2] acquired in Boston, USA.
Evaluation data: validation (20%) and test (80%) datasets were acquired from multiple hospitals in Denmark [3], with MRI sequences and labeling protocols identical to those used for finetuning, but originating from different institutions and geographic regions, thereby constituting an out-of-domain evaluation setting.
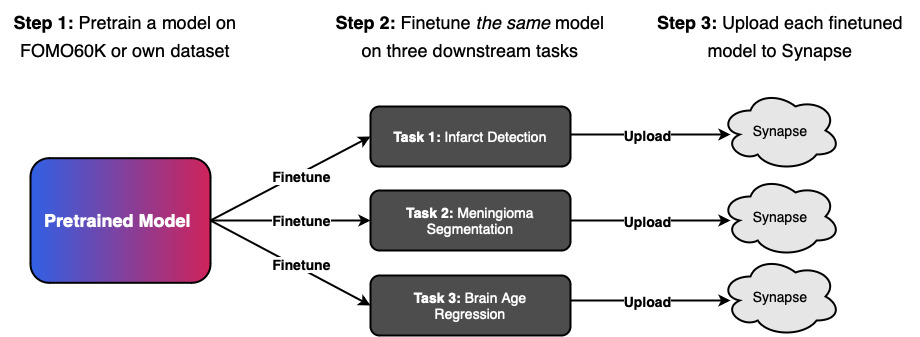
Participants submit inference-only Apptainer containers for evaluation. The organizers provide: baseline implementations, preprocessing code, container validation tools.
Results
The challenge received:
- 137 registrations
- 18 teams
- 19 evaluated foundation models
For each task, two fully supervised baseline are provided.
- Supervised-OOD, the model is trained on the out-of-domain finetune dataset (same data as the challenge participants)
- Supervised-ID, trained on the validation dataset (kept private), which is in-domain and notably larger than the finetune dataset.
Rankings and Statistical Analysis. Submissions were ranked by first averaging metric-specific ranks within each task, and then across tasks to obtain an overall ranking. Ranking stability was assessed using 10,000 bootstrap resamples of test cases, recomputing ranks to derive 95% confidence intervals. Statistical significance between submissions was evaluated using pairwise two-sided permutation testing (100,000 permutations) with Phipson-Smyth correction
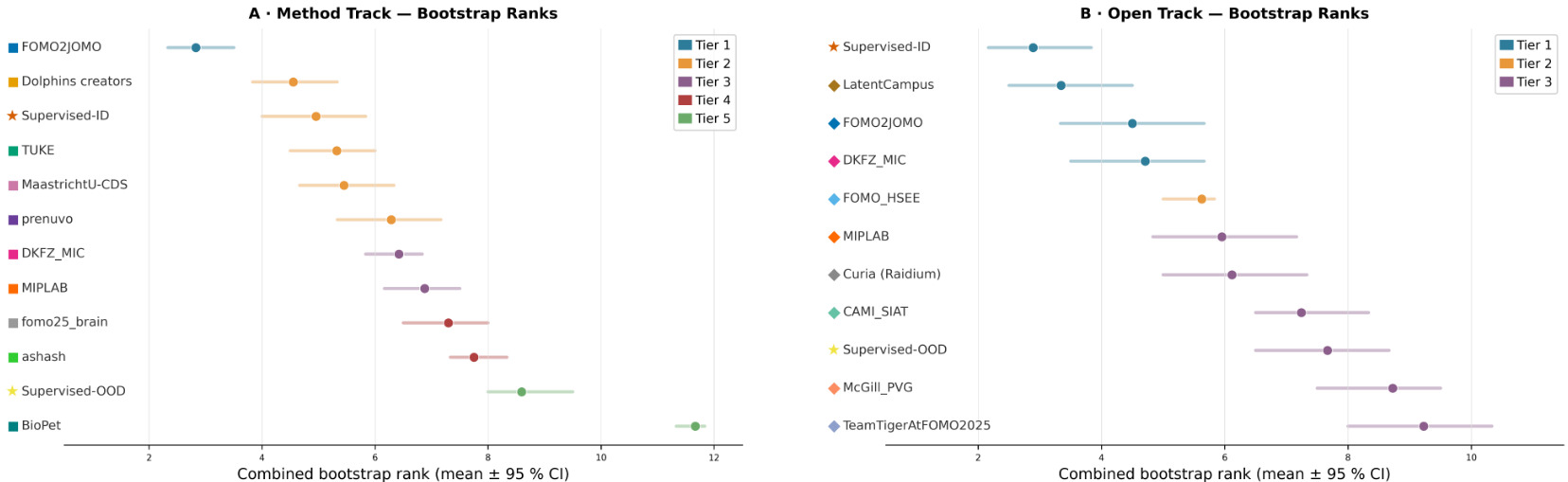
Main findings
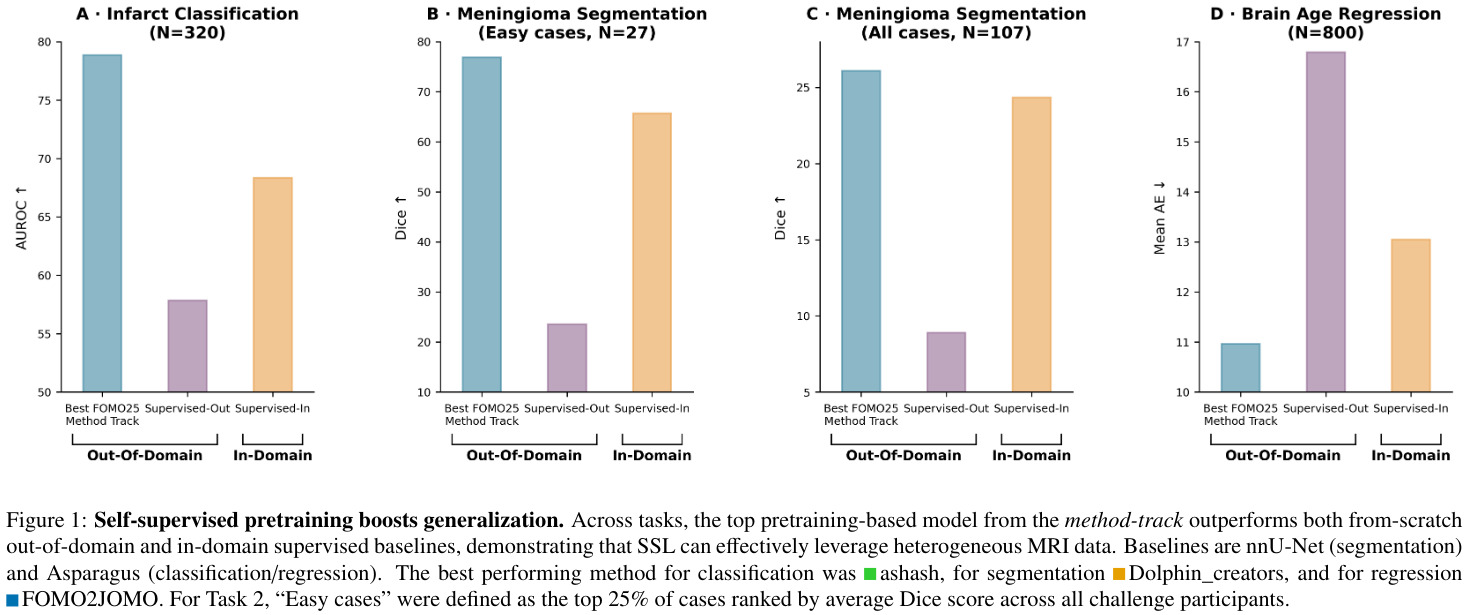
1. Self-supervised pretraining improves generalization
Foundation models consistently outperform Supervised-OOD baselines trained on the same out-of-domain finetuning data. Some SSL models even outperform Supervised-ID models.
SSL pretraining can compensate for severe domain shifts and limited labels.
2. No single SSL objective dominates all tasks
The authors categorize SSL objectives into:
- Local objectives: voxel-level supervision (e.g. MAE).
- Global objectives: sequence-level representation learning (e.g. contrastive learning).
- Hybrid objectives: combinations of local and global objectives.
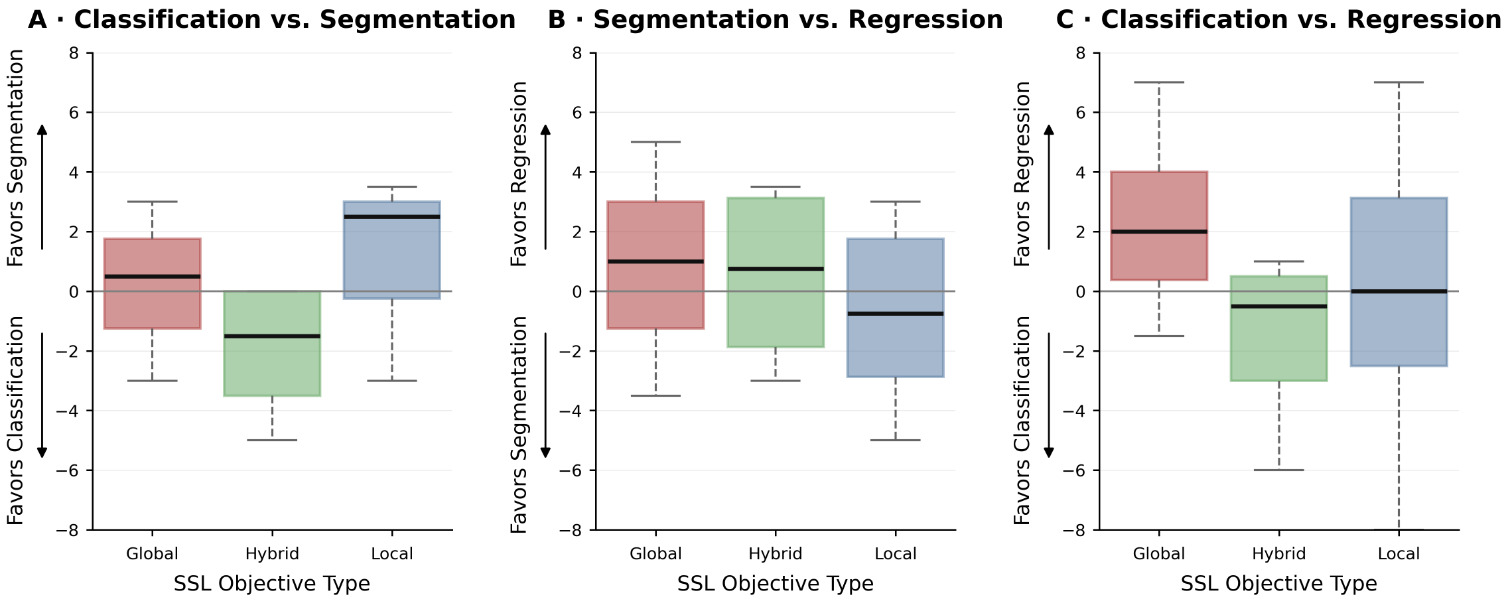 (A–C) Pairwise rank differences between tasks, grouped by SSL objective category (global, hybrid, local): classification vs. segmentation (A), segmentation vs. regression (B), and classification vs. regression (C).
(A–C) Pairwise rank differences between tasks, grouped by SSL objective category (global, hybrid, local): classification vs. segmentation (A), segmentation vs. regression (B), and classification vs. regression (C).
Observed trends:
- MAE-like local objectives favor segmentation over classification.
- Hybrid objectives favor classification and regression.
- Global objectives surprisingly seem to favor segmentation over classification (unlike natural image segmentation).
Pretraining objectives strongly interact with downstream task characteristics, but none dominates across tasks.
3. Scaling laws are weak
Increasing the number of pretraining samples seen does not reliably improve results. The authors suggest that many methods saturate early.
Larger encoders show only weak correlation with downstream performance. Even models with relatively small parameter counts achieve strong rankings. This contrasts with trends in large-scale computer vision and language models.
This suggests that data characteristics, objective design and adaptation strategy may matter more than scale in current medical imaging setups.
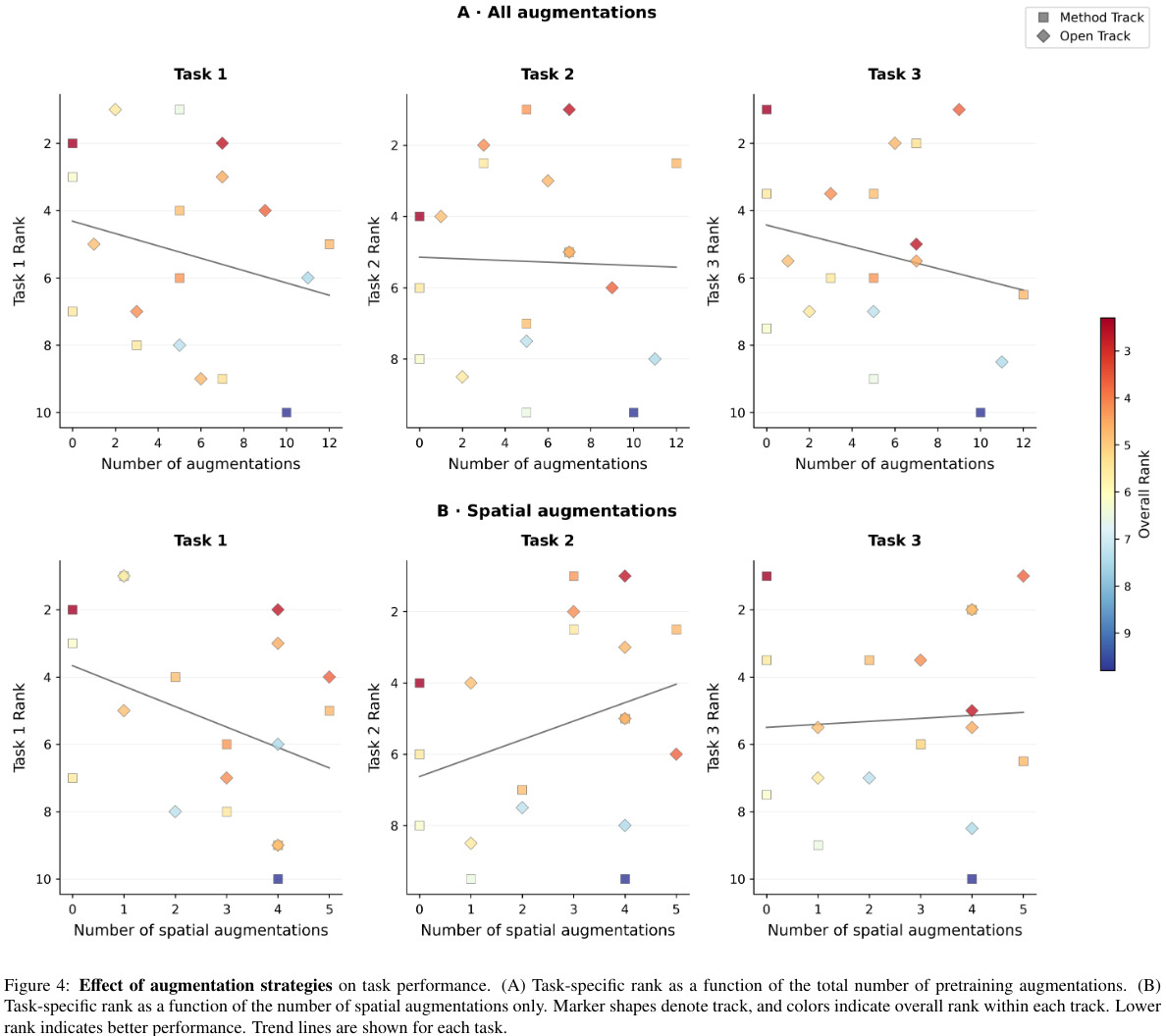
4. Augmentations
Spatial augmentations improve segmentation performance. However, excessive augmentations negatively affect classification and regression. This again highlights task-dependent behavior.
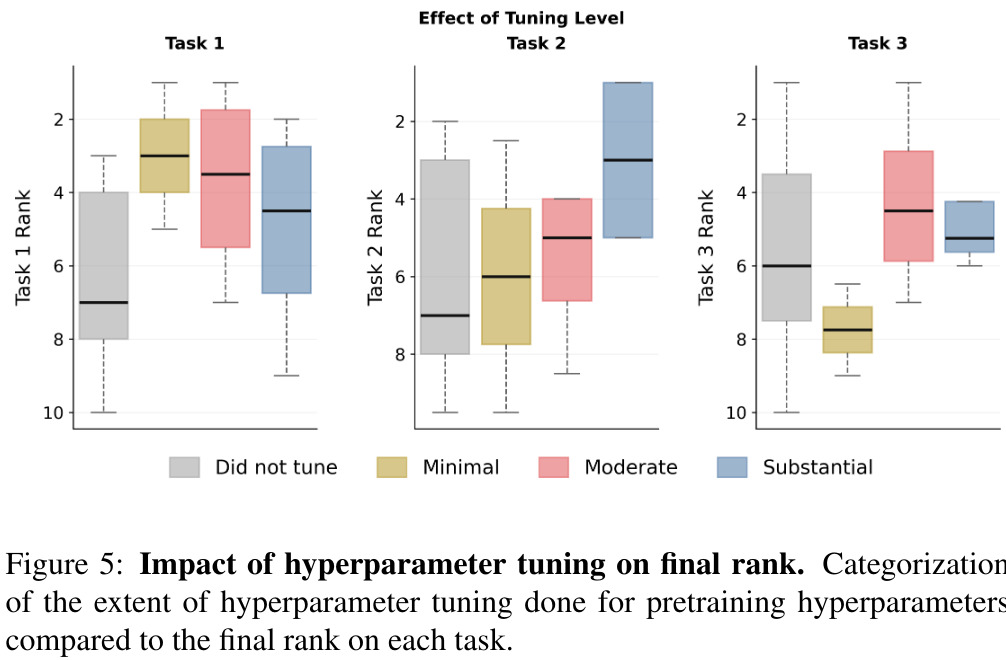
5. Hyperparameter Tuning
There is no universally optimal tuning strategy.
Conclusion, limitations and future work
FOMO2025 proposed a clinically realistic benchmark leveraging a large heterogeneous dataset leaing to valuable empirical insights about SSL objectives for downstream tasks on 3D MRI.
Yet, some limitations remain:
- The difference between Method and Open Tracks is less informative than expected. Many Open Track models were pretrained on datasets of similar scale.
- Difficult to isolate effects of pretraining from finetuning,
- Only one task per task family
- Limited conclusions about scaling
- Challenge-style comparisons can introduce engineering bias.
- Limited participations with high methodological diversity
- Underexplored directions: transformer-based architectures (CNNs dominate most submissions), 3D self-distillation, large-scale multimodal pretraining.
What’s next? FOMO2026!
“Same core philosophy as FOMO25, now expanded with 306,207 brain MRI scans for pretraining and seven downstream tasks evaluating generalization in realistic clinical settings.”
References
[1] S. Cerri, A. Munk, S. N. Llambias, J. Ambsdorf, J. Machnio, V. Nersesjan, C. Hedeager Krag, P. Liu, P. Rocamora García, M. Mehdipour Ghazi, M. Boesen, M. E. Benros, J. E. Iglesias, M. Nielsen, A largescale heterogeneous 3D magnetic resonance brain imaging dataset for self-supervised learning, arXiv preprint arXiv:2506.14432 (2026). URL: https://arxiv.org/ abs/2506.14432.
[2] J. E. Iglesias, B. Billot, Y. Balbastre, C. Magdamo, S. E. Arnold, S. Das, B. L. Edlow, D. C. Alexander, P. Golland, B. Fischl, SynthSR: A public AI tool to turn heterogeneous clinical brain scans into high-resolution T1weighted images for 3D morphometry, Science advances 9 (2023) eadd3607.
[3] S. Cerri, V. Nersesjan, K. V. Klein, E. C. Cóppulo, S. N. Llambias, M. M. Ghazi, M. Nielsen, M. E. Benros, Crossdisorder comparison of brain structures among 4,836 individuals with mental disorders and controls utilizing danish population-based clinical mri scans, Molecular Psychiatry (2026).