A visual–language foundation model for pathology image analysis using medical Twitter
Notes
- Official demo website (including links to the pretrained model, GitHub code, and dataset) is available on Hugging Face via this link.
- Published in Nature Medicine (IF: 87) > Nature (IF: 70). 😉
Highlights
- Introduce a large dataset (~200k) of pathology images with natural language descriptions.
- Introduce the first pre-trained foundation model (fine-tuned from pre-trained CLIP1) specialized for pathology images with both image and text understanding, named as pathology language–image pretraining (PLIP).
Introduction
Limitation of AI-enhanced diagnoses from routinely stained hematoxylin and eosin (H&E) images:
- lack of diversified datasets that include well-annotated labels in natural language considering that there are more than 8,000 diseases.
At the same time, many de-identified pathology images are shared on the Internet, especially on social media (e.g., Twitter), where clinicians discuss de-identified medical images with their colleagues.
Creation of OpenPath dataset
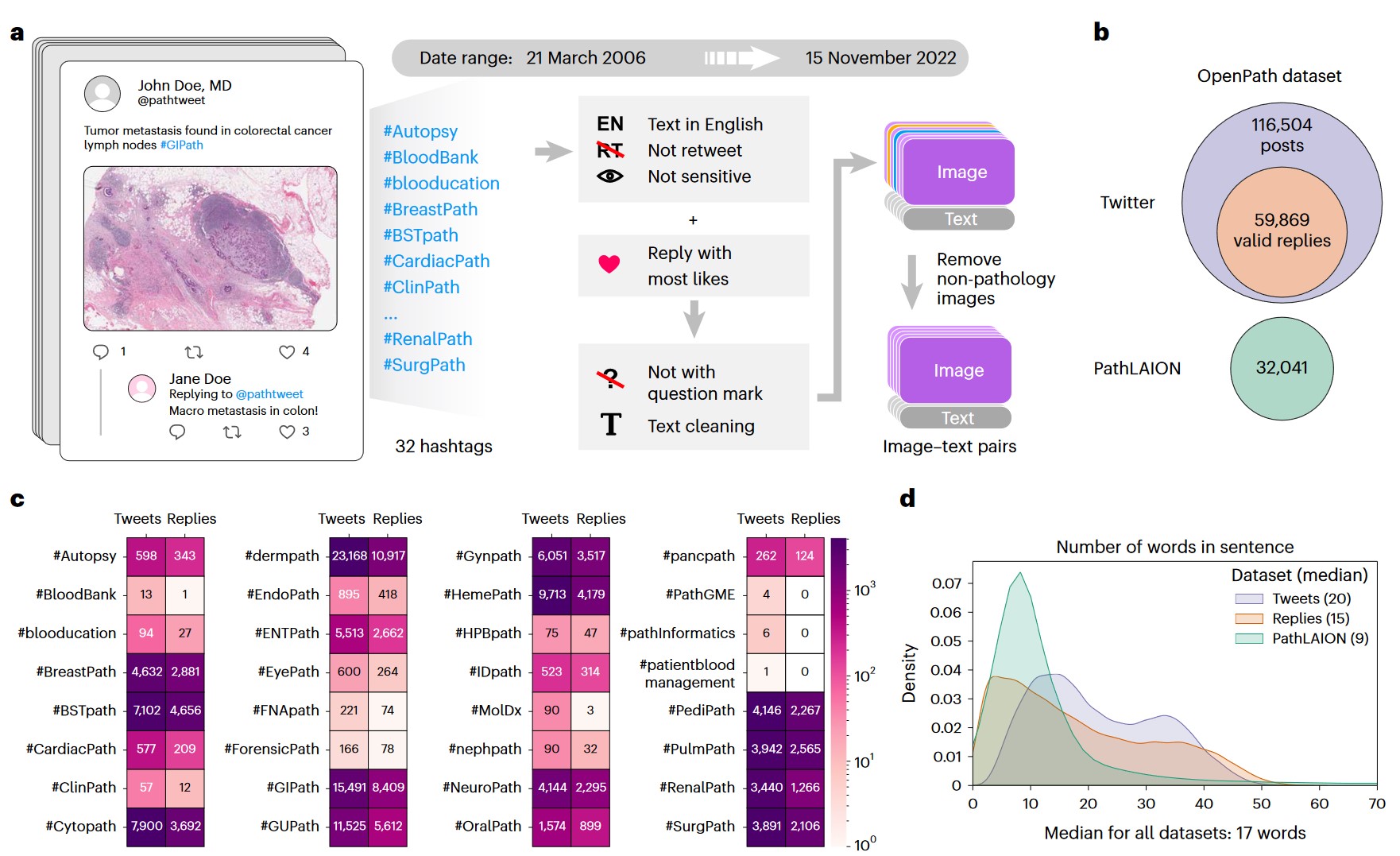 a) Flowchart of data acquisition from medical Twitter. b) Overview of the OpenPath dataset. c) Total number of available image–text pairs from tweets and replies within each Twitter hashtag (sorted in alphabetical order). Replies are those that received the highest number of likes in Twitter posts, if applicable. d) Density plot of the number of words per sentence in the OpenPath dataset.
a) Flowchart of data acquisition from medical Twitter. b) Overview of the OpenPath dataset. c) Total number of available image–text pairs from tweets and replies within each Twitter hashtag (sorted in alphabetical order). Replies are those that received the highest number of likes in Twitter posts, if applicable. d) Density plot of the number of words per sentence in the OpenPath dataset.
- Usage of the popular pathology Twitter hashtags to obtain 243,375 public pathology images;
- Expansion of the collection to include pathology data from other sites on the Internet (collected from the Large-scale Artificial Intelligence Open Network (LAION22));
- Strict data quality filtering;
- Creation of a collection of 208,414 pathology image–text pairs called OpenPath (largest publicly available pathology image collection that is annotated with text descriptions).
Methods
Architecture
 e) The process of training the PLIP model with paired image–text dataset via contrastive learning. f) Graphical demonstration of the contrastive learning training process
e) The process of training the PLIP model with paired image–text dataset via contrastive learning. f) Graphical demonstration of the contrastive learning training process
- Fine-tune CLIP using contrastive learning on OpenPath dataset;
- Input images resized to 224 \(\times\) 224 pixels;
- ViT-B/32 as image encoder and text transformer as the text encoder (maximum sequence length = 76 tokens).
Benchmarking datasets
Zero-shot classification & Linear probing:
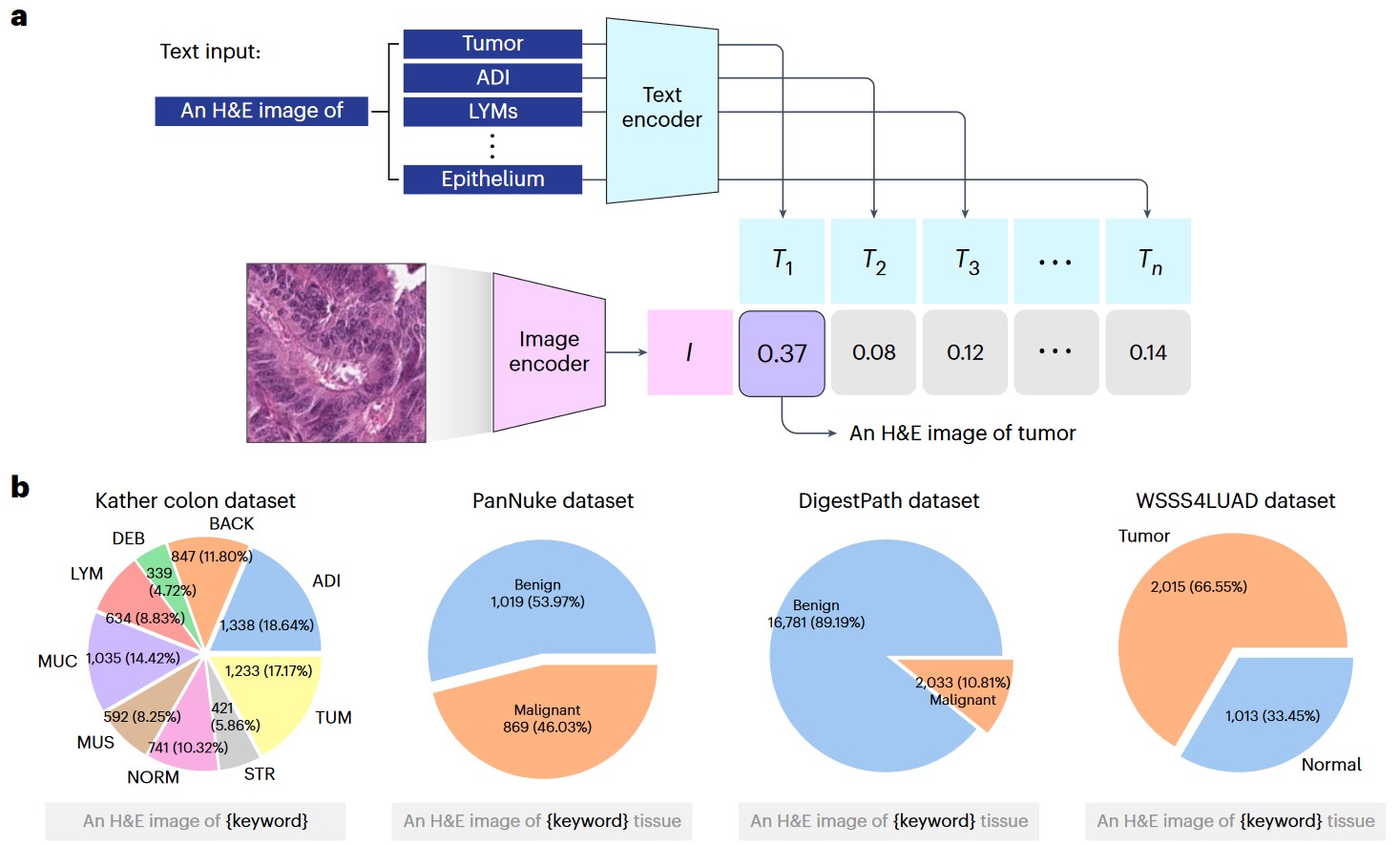 a) Graphical illustration of zero-shot classification. The classification output is determined by selecting the candidate text with the highest cosine similarity to the input image. b) Four external validation datasets: Kather colon dataset with nine tissue types; PanNuke dataset (benign and malignant tissues); DigestPath dataset (benign and malignant tissues); and WSSS4LUAD dataset (tumor and normal tissues).
a) Graphical illustration of zero-shot classification. The classification output is determined by selecting the candidate text with the highest cosine similarity to the input image. b) Four external validation datasets: Kather colon dataset with nine tissue types; PanNuke dataset (benign and malignant tissues); DigestPath dataset (benign and malignant tissues); and WSSS4LUAD dataset (tumor and normal tissues).
 e) Graphical illustration of linear probing transfer learning. ‘Frozen’ means that the loss from the linear classifier will not be used to update the parameters of the image encoder.
e) Graphical illustration of linear probing transfer learning. ‘Frozen’ means that the loss from the linear classifier will not be used to update the parameters of the image encoder.
- Kather colon dataset - 100,000 training image patches and 7,180 validation image patches;
- PanNuke dataset - 19 organ types with five different types of nuclei (neoplastic, inflammatory, connective tissue, epithelial and dead), a total of 7,558 image patches that contained at least one cell;
- DigestPath - 6,690 malignant images and 56,023 benign images;
- WSSS4LUAD - 6,579 tumor images and 3,512 normal images.
ⓘ Random 70/30 train/val split for all datasets except Kather colon dataset, which has its own validation split.
Text-to-image retrieval analysis:
 a) Graphical illustration of pathology image retrieval from text input. b) Density plot of the number of words per sentence across the four validation datasets.
a) Graphical illustration of pathology image retrieval from text input. b) Density plot of the number of words per sentence across the four validation datasets.
- Twitter validation dataset;
- PathPedia - 210 image-text pairs;
- Pathology collections of PubMed and Books.
Image-to-image retrieval analysis (evaluate the model’s ability to retrieve images with the same textural pattern):
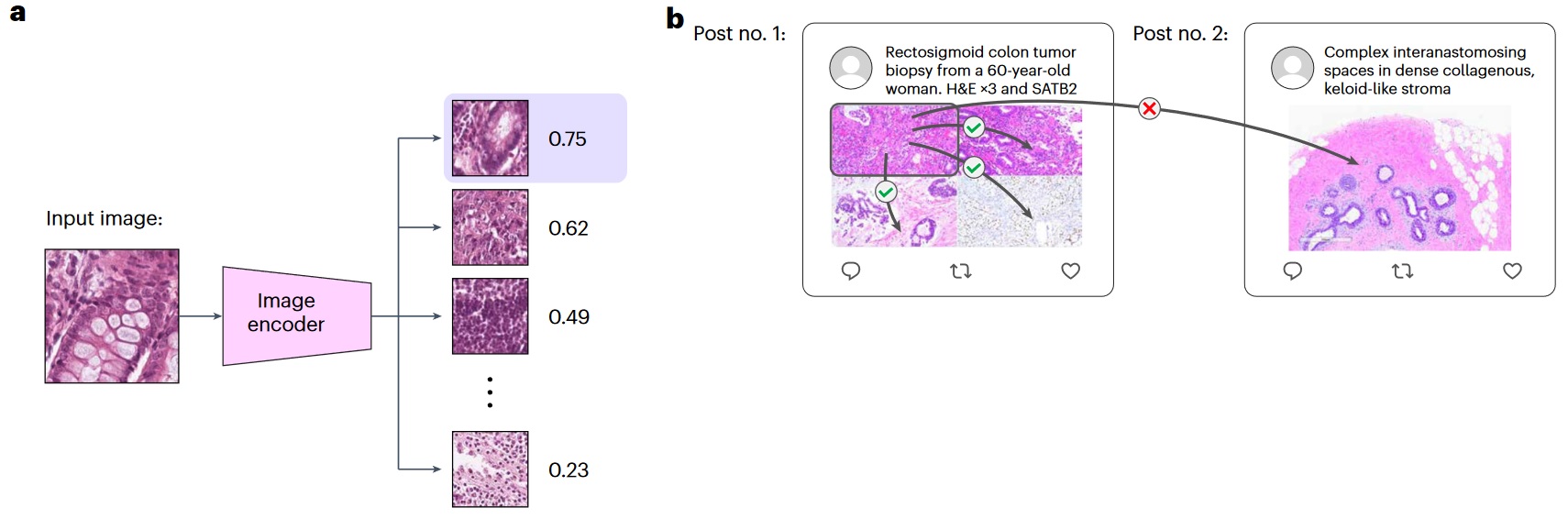 a) Graphical illustration of image-to-image retrieval. b) Illustration of image-to-image retrieval analysis on the Twitter validation dataset.
a) Graphical illustration of image-to-image retrieval. b) Illustration of image-to-image retrieval analysis on the Twitter validation dataset.
- Kather colon dataset - 9 different tissue types;
- PanNuke dataset - 19 different organ types;
- KIMIA Path24C dataset - 24 different pathology image staining textures.
Results
The performance of CLIP was compared with CLIP (also trained with medical images), MuDiPath (multitask pretraining deep neural network model with DenseNet121 architecture, which was trained on a collection of 22 digital pathology classification tasks with approximately 900,000 images), and task-specific fully supervised ViT-B/32.
Zero-shot classification
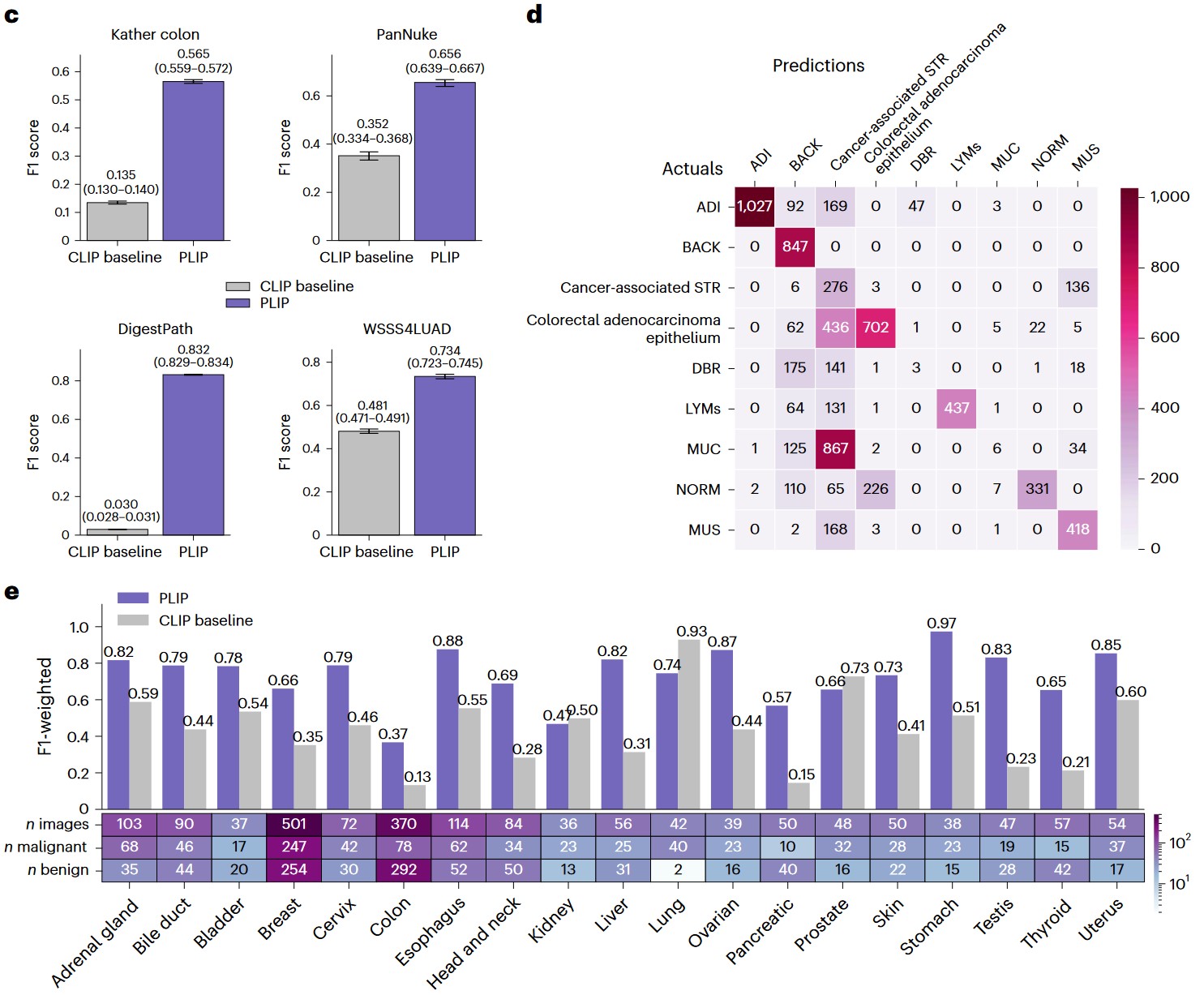 c) Zero-shot performances with weighted F1 scores across the four datasets. Note that the performances in the Kather colon dataset are based on a nineclass zero-shot learning evaluation, while the performances for other datasets are based on binary zero-shot learning evaluation. Within each box plot, the center line represents the mean and the error bar indicates the 95% CI. Number of test samples for each dataset: Kather colon (n = 7,180); PanNuke (n = 1,888); DigestPath (n = 18,814); and WSSS4LUAD (n = 3,028). d) Confusion matrix of the Kather colon dataset. The actual and predicted labels are displayed in rows and columns, respectively. e) Zero-shot evaluation of the PanNuke dataset within each organ type.
c) Zero-shot performances with weighted F1 scores across the four datasets. Note that the performances in the Kather colon dataset are based on a nineclass zero-shot learning evaluation, while the performances for other datasets are based on binary zero-shot learning evaluation. Within each box plot, the center line represents the mean and the error bar indicates the 95% CI. Number of test samples for each dataset: Kather colon (n = 7,180); PanNuke (n = 1,888); DigestPath (n = 18,814); and WSSS4LUAD (n = 3,028). d) Confusion matrix of the Kather colon dataset. The actual and predicted labels are displayed in rows and columns, respectively. e) Zero-shot evaluation of the PanNuke dataset within each organ type.
Linear probing
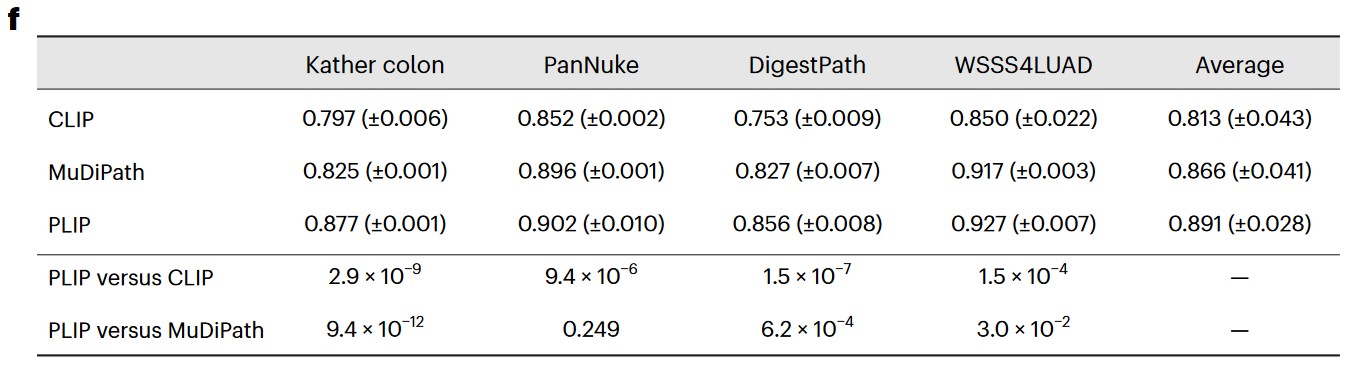 f) F1 score in testing sets with the mean (± s.d.) from five repeated experiments with different random seeds. The ‘Average’ column shows the averaged performances across the four datasets. P values were calculated using a two-sided Student’s t-test and are presented in the bottom two rows.
f) F1 score in testing sets with the mean (± s.d.) from five repeated experiments with different random seeds. The ‘Average’ column shows the averaged performances across the four datasets. P values were calculated using a two-sided Student’s t-test and are presented in the bottom two rows.
Text-to-image retrieval analysis
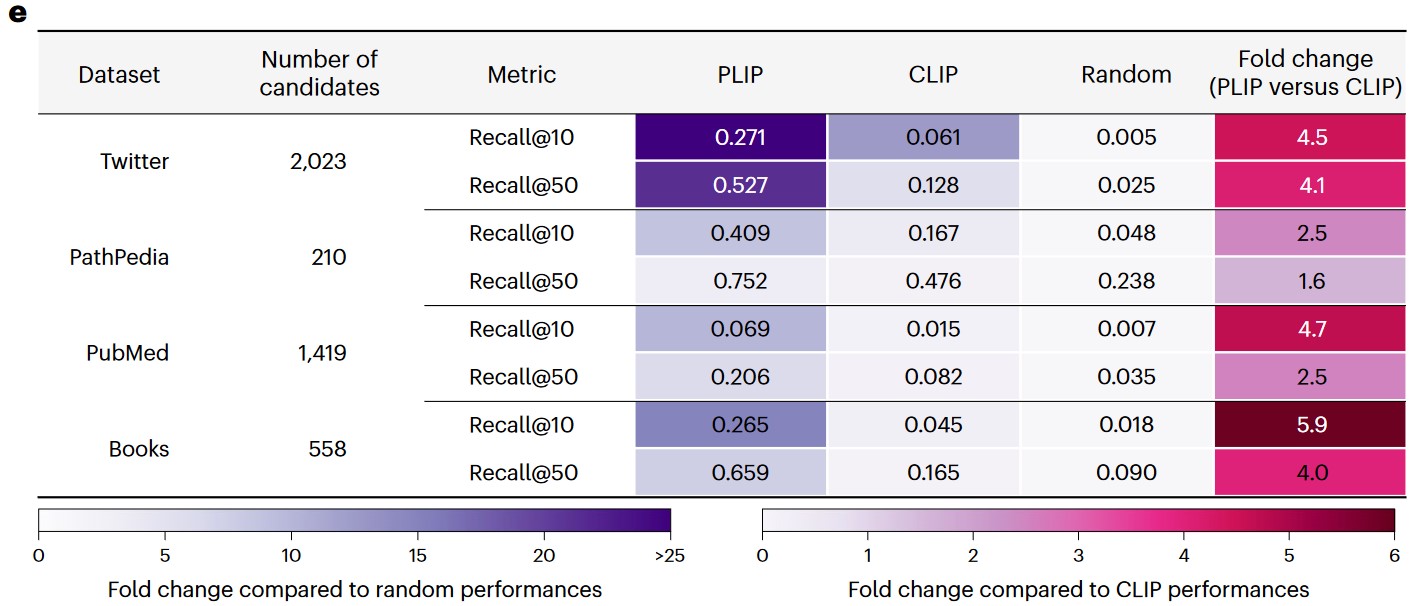 e) Image retrieval performances across the validation datasets.
e) Image retrieval performances across the validation datasets.
Image-to-image retrieval analysis
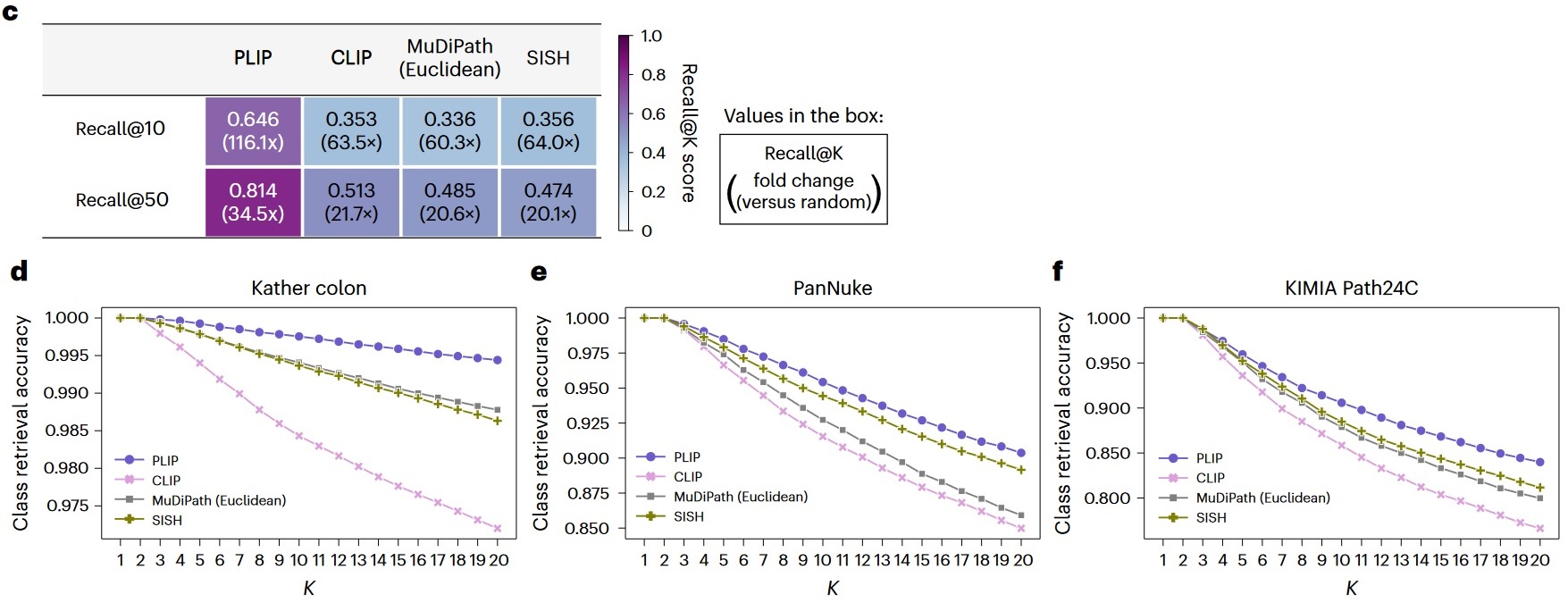 c) Image-to-image retrieval performances on the Twitter validation dataset. The values in the boxes represent the Recall@10 and Recall@50 scores and the fold changes compared to random performances. d) Image-to-image retrieval performances on the Kather colon dataset. e) Image-to-image retrieval performances on the PanNuke dataset. f) Image-to-image retrieval performances on the KIMIA Path24C dataset.
c) Image-to-image retrieval performances on the Twitter validation dataset. The values in the boxes represent the Recall@10 and Recall@50 scores and the fold changes compared to random performances. d) Image-to-image retrieval performances on the Kather colon dataset. e) Image-to-image retrieval performances on the PanNuke dataset. f) Image-to-image retrieval performances on the KIMIA Path24C dataset.
Comparison to supervised models
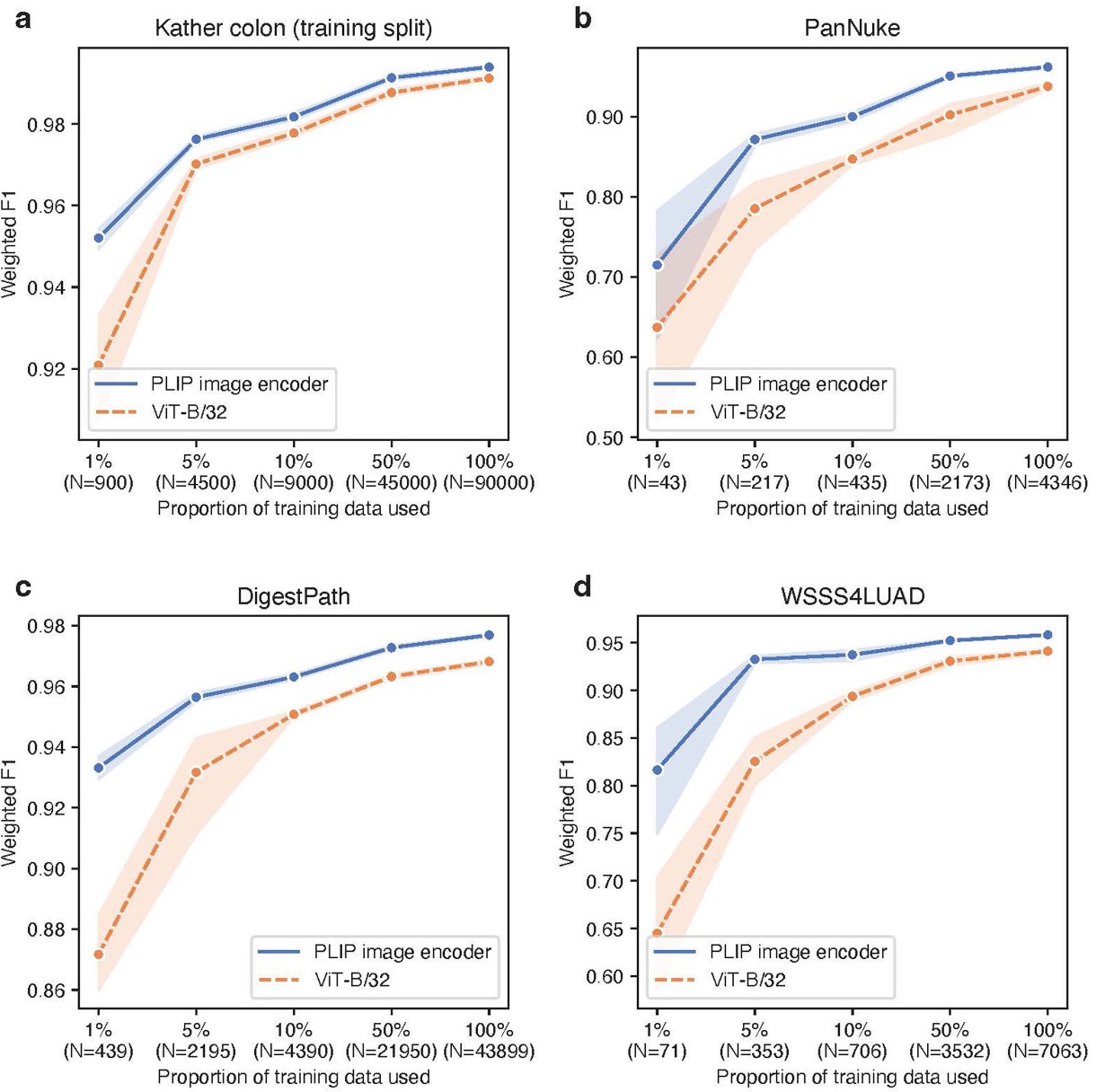 Comparison to supervised deep learning models. The fine-tuning was conducted on a) Kather colon dataset training split, b) PanNuke dataset, c) DigestPath dataset, and d) WSSS4LUAD dataset, by comparing the PLIP image encoder to ViT-B/32 (pre-trained on ImageNet).
Comparison to supervised deep learning models. The fine-tuning was conducted on a) Kather colon dataset training split, b) PanNuke dataset, c) DigestPath dataset, and d) WSSS4LUAD dataset, by comparing the PLIP image encoder to ViT-B/32 (pre-trained on ImageNet).
Conclusions
The authors proposed a public large scale H&E pathology images dataset, OpenPath, that is annotated with natural language descriptions, and a pathology language–image pretraining (PLIP) model by fine-tuning CLIP on the OpenPath dataset. The PLIP model achieved state-of-the-art performance on zero-shot classification, linear probing, text-to-image retrieval and image-to-image retrieval tasks. The PLIP model also outperformed the supervised models in the fine-tuning experiments. The PLIP model can be used as a foundation model for pathology image analysis.